Zlepšení reaktivity pomocí Redis client-side cache
Co je Redis?
Předpokládám, že málokdo nezná Redis. Přesto, abychom ho stručně zmínili s několika jeho vlastnostmi, lze jej shrnout následovně:
- Operace jsou prováděny v jednom vlákně, což zajišťuje atomicitu všech operací.
- Data jsou ukládána a zpracovávána In-Memory, což zajišťuje rychlost všech operací.
- Redis může ukládat WAL v závislosti na konfiguraci, což umožňuje rychlé zálohování a obnovu nejnovějšího stavu.
- Podporuje různé datové typy, jako jsou Set, Hash, Bit, List, což vede k vysoké produktivitě.
- Má velkou komunitu, což umožňuje sdílení různých zkušeností, problémů a řešení.
- Je dlouhodobě vyvíjen a provozován, což zajišťuje spolehlivou stabilitu.
Takže k věci
Představte si to
Co kdyby cache vaší služby splňovala následující dvě podmínky?
- Je nutné poskytovat uživatelům často dotazovaná data v nejnovějším stavu, ale obnova je nepravidelná, což vyžaduje častou aktualizaci cache.
- Aktualizace se neprovádí, ale je nutné často přistupovat a dotazovat se na stejná data v cache.
První případ může zohledňovat žebříček populárních produktů v reálném čase v internetovém obchodě. Pokud je žebříček populárních produktů v reálném čase uložen jako sorted set, je neefektivní, aby jej Redis četl pokaždé, když uživatel přistoupí na hlavní stránku. Druhý případ se týká kurzovních dat: i když jsou kurzovní data oznamována přibližně každých 10 minut, skutečné dotazy se vyskytují velmi často. Zejména pro kurzy won-dolar, won-jen a won-yuan dochází k velmi častým dotazům do cache. V těchto případech by bylo efektivnější, kdyby API server udržoval samostatnou lokální cache a při změně dat znovu dotazoval Redis a aktualizoval ji.
Jak tedy můžeme implementovat takové chování v architektuře databáze - Redis - API server?
Co takhle Redis PubSub?
Při použití cache se přihlasme k odběru kanálu, který může přijímat informace o aktualizacích!
- Pak je třeba vytvořit logiku pro odesílání zpráv při aktualizaci.
- Dodatečné operace způsobené PubSubem ovlivňují výkon.
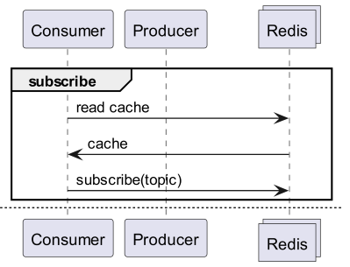
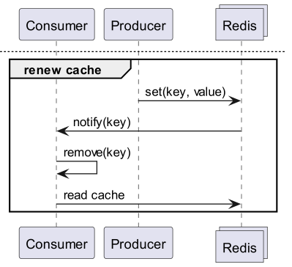
Co když Redis detekuje změnu?
Co když použijeme Keyspace Notification k přijímání oznámení o příkazech pro daný klíč?
- Existuje obtížnost předběžného uložení a sdílení klíčů a příkazů používaných pro aktualizaci.
- Například pro některé klíče je jednoduchý Set příkazem pro aktualizaci, zatímco pro jiné klíče je to LPush, RPush, SAdd nebo SRem, což se stává složitým.
- To výrazně zvyšuje pravděpodobnost komunikačních chyb a lidských chyb při kódování během vývojového procesu.
Co když použijeme Keyevent Notification k přijímání oznámení na úrovni příkazů?
- Je nutné se přihlásit k odběru všech příkazů používaných pro aktualizaci. Je nutné řádně filtrovat klíče, které přicházejí.
- Například pro některé klíče přicházející s Del je vysoká pravděpodobnost, že daný klient nemá lokální cache.
- To může vést k zbytečnému plýtvání zdroji.
Proto je nezbytná Invalidation Message!
Co je Invalidation Message?
Invalidation Messages je koncept zavedený jako součást Server Assisted Client-Side Cache, který byl přidán od Redis 6.0. Invalidation Message je doručena následujícím způsobem:
- Předpokládejme, že ClientB již jednou přečetl klíč.
- ClientA nastaví nový klíč.
- Redis detekuje změnu a publikuje Invalidation Message pro ClientB, aby mu oznámil, aby vymazal cache.
- ClientB obdrží tuto zprávu a provede příslušnou akci.
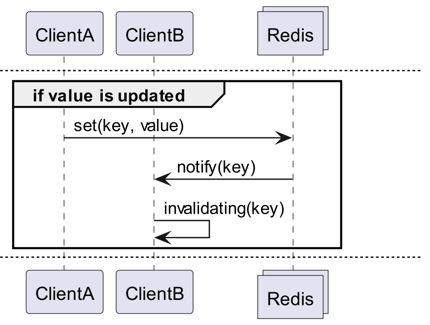
Jak se to používá?
Základní princip fungování
Klient připojený k Redisu obdrží invalidation message spuštěním CLIENT TRACKING ON REDIRECT <client-id>. Klient, který má přijímat zprávy, se přihlásí k odběru invalidation message pomocí SUBSCRIBE __redis__:invalidate.
default tracking
1# client 1
2> SET a 100
1# client 3
2> CLIENT ID
312
4> SUBSCRIBE __redis__:invalidate
51) "subscribe"
62) "__redis__:invalidate"
73) (integer) 1
1# client 2
2> CLIENT TRACKING ON REDIRECT 12
3> GET a # tracking
1# client 1
2> SET a 200
1# client 3
21) "message"
32) "__redis__:invalidate"
43) 1) "a"
broadcasting tracking
1# client 3
2> CLIENT ID
312
4> SUBSCRIBE __redis__:invalidate
51) "subscribe"
62) "__redis__:invalidate"
73) (integer) 1
1# client 2
2CLIENT TRACKING ON BCAST PREFIX cache: REDIRECT 12
1# client 1
2> SET cache:name "Alice"
3> SET cache:age 26
1# client 3
21) "message"
32) "__redis__:invalidate"
43) 1) "cache:name"
51) "message"
62) "__redis__:invalidate"
73) 1) "cache:age"
Implementace! Implementace! Implementace!
Redigo + Ristretto
Pokud by to bylo vysvětleno pouze takto, bylo by nejasné, jak to použít v kódu. Proto to nejprve jednoduše nakonfigurujeme s redigo a ristretto.
Nejprve nainstalujte dvě závislosti.
github.com/gomodule/redigogithub.com/dgraph-io/ristretto
1package main
2
3import (
4 "context"
5 "fmt"
6 "log/slog"
7 "time"
8
9 "github.com/dgraph-io/ristretto"
10 "github.com/gomodule/redigo/redis"
11)
12
13type RedisClient struct {
14 conn redis.Conn
15 cache *ristretto.Cache[string, any]
16 addr string
17}
18
19func NewRedisClient(addr string) (*RedisClient, error) {
20 cache, err := ristretto.NewCache(&ristretto.Config[string, any]{
21 NumCounters: 1e7, // počet klíčů pro sledování frekvence (10M).
22 MaxCost: 1 << 30, // maximální cena cache (1GB).
23 BufferItems: 64, // počet klíčů na Get buffer.
24 })
25 if err != nil {
26 return nil, fmt.Errorf("failed to generate cache: %w", err)
27 }
28
29 conn, err := redis.Dial("tcp", addr)
30 if err != nil {
31 return nil, fmt.Errorf("failed to connect to redis: %w", err)
32 }
33
34 return &RedisClient{
35 conn: conn,
36 cache: cache,
37 addr: addr,
38 }, nil
39}
40
41func (r *RedisClient) Close() error {
42 err := r.conn.Close()
43 if err != nil {
44 return fmt.Errorf("failed to close redis connection: %w", err)
45 }
46
47 return nil
48}
Nejprve jednoduše vytvoříme RedisClient obsahující ristretto a redigo.
1func (r *RedisClient) Tracking(ctx context.Context) error {
2 psc, err := redis.Dial("tcp", r.addr)
3 if err != nil {
4 return fmt.Errorf("failed to connect to redis: %w", err)
5 }
6
7 clientId, err := redis.Int64(psc.Do("CLIENT", "ID"))
8 if err != nil {
9 return fmt.Errorf("failed to get client id: %w", err)
10 }
11 slog.Info("client id", "id", clientId)
12
13 subscriptionResult, err := redis.String(r.conn.Do("CLIENT", "TRACKING", "ON", "REDIRECT", clientId))
14 if err != nil {
15 return fmt.Errorf("failed to enable tracking: %w", err)
16 }
17 slog.Info("subscription result", "result", subscriptionResult)
18
19 if err := psc.Send("SUBSCRIBE", "__redis__:invalidate"); err != nil {
20 return fmt.Errorf("failed to subscribe: %w", err)
21 }
22 psc.Flush()
23
24 for {
25 msg, err := psc.Receive()
26 if err != nil {
27 return fmt.Errorf("failed to receive message: %w", err)
28 }
29
30 switch msg := msg.(type) {
31 case redis.Message:
32 slog.Info("received message", "channel", msg.Channel, "data", msg.Data)
33 key := string(msg.Data)
34 r.cache.Del(key)
35 case redis.Subscription:
36 slog.Info("subscription", "kind", msg.Kind, "channel", msg.Channel, "count", msg.Count)
37 case error:
38 return fmt.Errorf("error: %w", msg)
39 case []interface{}:
40 if len(msg) != 3 || string(msg[0].([]byte)) != "message" || string(msg[1].([]byte)) != "__redis__:invalidate" {
41 slog.Warn("unexpected message", "message", msg)
42 continue
43 }
44
45 contents := msg[2].([]interface{})
46 keys := make([]string, len(contents))
47 for i, key := range contents {
48 keys[i] = string(key.([]byte))
49 r.cache.Del(keys[i])
50 }
51 slog.Info("received invalidation message", "keys", keys)
52 default:
53 slog.Warn("unexpected message", "type", fmt.Sprintf("%T", msg))
54 }
55 }
56}
Kód je trochu složitý.
- Pro Tracking se navazuje další spojení. To je opatření, které zohledňuje možnost, že PubSub bude rušit jiné operace.
- Dotazováním ID přidaného spojení se Tracking přesměruje na toto spojení z připojení, které bude dotazovat data.
- Poté se přihlásí k odběru invalidation message.
- Kód pro zpracování odběru je trochu složitý. Jelikož redigo nepodporuje parsování invalidation message, je nutné přijmout odpověď před parsováním a zpracovat ji.
1func (r *RedisClient) Get(key string) (any, error) {
2 val, found := r.cache.Get(key)
3 if found {
4 switch v := val.(type) {
5 case int64:
6 slog.Info("cache hit", "key", key)
7 return v, nil
8 default:
9 slog.Warn("unexpected type", "type", fmt.Sprintf("%T", v))
10 }
11 }
12 slog.Info("cache miss", "key", key)
13
14 val, err := redis.Int64(r.conn.Do("GET", key))
15 if err != nil {
16 return nil, fmt.Errorf("failed to get key: %w", err)
17 }
18
19 r.cache.SetWithTTL(key, val, 1, 10*time.Second)
20 return val, nil
21}
Zpráva Get nejprve dotazuje ristretto, a pokud není nalezena, pak ji získá z Redis.
1package main
2
3import (
4 "context"
5 "log/slog"
6 "os"
7 "os/signal"
8 "time"
9)
10
11func main() {
12 ctx, cancel := signal.NotifyContext(context.Background(), os.Interrupt)
13 defer cancel()
14
15 client, err := NewRedisClient("localhost:6379")
16 if err != nil {
17 panic(err)
18 }
19 defer client.Close()
20
21 go func() {
22 if err := client.Tracking(ctx); err != nil {
23 slog.Error("failed to track invalidation message", "error", err)
24 }
25 }()
26
27 ticker := time.NewTicker(1 * time.Second)
28 defer ticker.Stop()
29 done := ctx.Done()
30
31 for {
32 select {
33 case <-done:
34 slog.Info("shutting down")
35 return
36 case <-ticker.C:
37 v, err := client.Get("key")
38 if err != nil {
39 slog.Error("failed to get key", "error", err)
40 return
41 }
42 slog.Info("got key", "value", v)
43 }
44 }
45}
Kód pro testování je výše. Pokud jej otestujete, uvidíte, že se hodnota aktualizuje pokaždé, když se data v Redis aktualizují.
To je však příliš složité. Především je nezbytné aktivovat Tracking pro všechny master nebo repliky, aby se rozšířilo na cluster.
Rueidis
Pokud používáme jazyk Go, máme k dispozici nejmodernější a nejrozvinutější rueidis. Nyní napíšeme kód, který používá server assisted client side cache v prostředí Redis clusteru s použitím rueidis.
Nejprve nainstalujte závislost.
github.com/redis/rueidis
A pak napište kód pro dotazování dat v Redis.
1package main
2
3import (
4 "context"
5 "log/slog"
6 "os"
7 "os/signal"
8 "time"
9
10 "github.com/redis/rueidis"
11)
12
13func main() {
14 ctx, cancel := signal.NotifyContext(context.Background(), os.Interrupt)
15 defer cancel()
16
17 client, err := rueidis.NewClient(rueidis.ClientOption{
18 InitAddress: []string{"localhost:6379"},
19 })
20 if err != nil {
21 panic(err)
22 }
23
24 ticker := time.NewTicker(1 * time.Second)
25 defer ticker.Stop()
26 done := ctx.Done()
27
28 for {
29 select {
30 case <-done:
31 slog.Info("shutting down")
32 return
33 case <-ticker.C:
34 const key = "key"
35 resp := client.DoCache(ctx, client.B().Get().Key(key).Cache(), 10*time.Second)
36 if resp.Error() != nil {
37 slog.Error("failed to get key", "error", resp.Error())
38 continue
39 }
40 i, err := resp.AsInt64()
41 if err != nil {
42 slog.Error("failed to convert response to int64", "error", err)
43 continue
44 }
45 switch resp.IsCacheHit() {
46 case true:
47 slog.Info("cache hit", "key", key)
48 case false:
49 slog.Info("missed key", "key", key)
50 }
51 slog.Info("got key", "value", i)
52 }
53 }
54}
V rueidis stačí pouze DoCache k použití client side cache. To přidá data do lokální cache a při opětovném volání DoCache se data získají z lokální cache. Samozřejmě, invalidation messages jsou také řádně zpracovány.
Proč ne redis-go?
redis-go bohužel nepodporuje server assisted client side cache prostřednictvím oficiálního API. Dokonce neexistuje API pro přímý přístup k nově vytvořenému připojení při vytváření PubSub, takže nelze získat client ID. Proto jsem usoudil, že redis-go nelze konfigurovat, a přeskočil jsem ho.
To je sexy
Prostřednictvím struktury client side cache
- Pokud jsou data, která lze předem připravit, pomocí této struktury, bude možné minimalizovat dotazy a provoz na Redis a vždy poskytovat nejnovější data.
- To umožní vytvořit jakousi CQRS strukturu a výrazně zlepšit výkon čtení.

O kolik se to zlepšilo?
Vzhledem k tomu, že se tato struktura již používá v praxi, jsem stručně prozkoumal latenci dvou API. Prosím, omluvte, že to mohu popsat pouze velmi abstraktně.
- První API
- Při prvním dotazu: průměrně 14.63 ms
- Při následných dotazech: průměrně 2.82 ms
- Průměrný rozdíl: 10.98 ms
- Druhé API
- Při prvním dotazu: průměrně 14.05 ms
- Při následných dotazech: průměrně 1.60 ms
- Průměrný rozdíl: 11.57 ms
Došlo k dalšímu zlepšení latence až o 82 %!
Očekávám, že došlo k následujícím vylepšením:
- Eliminace síťové komunikace mezi klientem a Redis a úspora provozu
- Snížení počtu příkazů pro čtení, které musí Redis provádět sám
- To má za následek i zlepšení výkonu zápisu.
- Minimalizace parsování protokolu Redis
- Parsování protokolu Redis není bez nákladů. Možnost to snížit je velká příležitost.
Všechno je však kompromis. Za to jsme obětovali minimálně následující dvě věci:
- Nutnost implementace, provozu a údržby komponent pro správu cache na straně klienta.
- Zvýšení využití CPU a paměti klienta v důsledku toho.
Závěr
Osobně jsem byl s architekturou spokojen a latence i zatížení API serveru byly velmi nízké. Do budoucna bych rád, pokud to bude možné, navrhoval architekturu s takovou strukturou.