Představujeme Randflake ID: distribuovaný, uniformní, nepředvídatelný, unikátní generátor náhodných ID.
Zvažme situaci, kdy potřebujeme generovat unikátní 64bitová náhodná čísla a externí strany by neměly být schopny předpovědět další nebo předchozí číslo.
Zde můžeme vygenerovat 8bajtovou náhodnou hodnotu, zkontrolovat, zda již existuje v databázi, a poté ji uložit, pokud je unikátní.
Tato metoda má však několik nevýhod. Musíme ukládat každé vygenerované číslo do databáze, abychom zajistili jeho jedinečnost. Požadavek na alespoň jednu cestu do databáze a zpět vytváří problémy s latencí, zejména v distribuovaném prostředí, kde je škálovatelnost klíčová.
K vyřešení těchto problémů představujeme Randflake ID: distribuovaný, uniformní, nepředvídatelný, unikátní generátor náhodných ID.
Jak funguje Randflake ID?
Randflake ID je inspirováno Snowflake ID, široce používaným mechanismem generování k-řazených ID vyvinutým společností X (dříve twitter).
Snowflake ID používá aktuální časové razítko, ID uzlu a lokální čítač k vygenerování identifikátoru.
Tento přístup jsme dále rozšířili pro generování náhodných unikátních ID a přidali nový prvek tajného klíče.
Klíčovou myšlenkou je přidání vrstvy blokové šifry k existujícímu generátoru unikátních ID, aby se dosáhlo nepředvídatelnosti vztahu mezi čísly.
Bloková šifra je základní kryptografická funkce, která transformuje blok prostého textu s pevnou délkou na blok šifrovaného textu stejné délky. Tato transformace je řízena kryptografickým klíčem. Rozlišujícím znakem blokové šifry je její reverzibilita: musí se jednat o jednoznačnou (bijektivní) funkci, která zajišťuje, že každý unikátní vstup odpovídá unikátnímu výstupu a naopak. Tato vlastnost je klíčová pro dešifrování, které umožňuje obnovit původní prostý text ze šifrovaného textu po aplikaci správného klíče.
Použitím blokové šifry jako jednoznačné funkce můžeme zaručit, že každý unikátní vstup produkuje odpovídající unikátní výstup v definovaném rozsahu.
Struktura a úvahy o návrhu
Na základě těchto základních konceptů se podívejme, jak Randflake ID implementuje tyto myšlenky v praxi.
Struktura Randflake ID zahrnuje 30bitové unixové časové razítko s přesností na sekundy, 17bitový identifikátor uzlu, 17bitový lokální čítač a 64bitovou blokovou šifru založenou na algoritmu sparx64.
Zde jsou některá rozhodnutí o návrhu:
Některé instance VM v Google Cloud Platform mohou synchronizovat hodiny s přesností 0,2 ms, ale tato úroveň přesnosti není dostupná na veřejném internetu ani u jiných poskytovatelů cloudu.
Zvolili jsme sekundovou přesnost, protože hodiny mezi uzly můžeme efektivně synchronizovat pouze s rozlišením několika milisekund.
17bitový identifikátor uzlu umožňuje 131072 jednotlivých generátorů v tentýž okamžik, které mohou být přiřazeny na bázi per-process, per-core, per-thread.
V systémech s vysokou propustností může být 17bitový lokální čítač nedostatečný. Pro dosažení odpovídající propustnosti můžeme přiřadit více generátorů, každý s odlišným ID uzlu, aby pracovaly v jediném procesu nebo vlákně.
Přijali jsme sparx64 jako 64bitovou blokovou šifru, moderní odlehčenou blokovou šifru založenou na ARX.
Randflake ID nabízí interní sledovatelnost, odhalující původní ID uzlu a časové razítko pouze těm, kteří vlastní tajný klíč.
Teoretická maximální propustnost je 17 179 869 184 ID/s, což je dostatečné pro většinu globálních aplikací.
Pseudokód generování Randflake ID
Pro další ilustraci procesu generování Randflake ID poskytuje následující pseudokód v Pythonu zjednodušenou implementaci:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Sunday, October 27, 2024 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bitů pro časové razítko (životnost 34 let)
10RANDFLAKE_NODE_BITS = 17 # 17 bitů pro ID uzlu (max 131072 uzlů)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bitů pro sekvenci (max 131072 sekvencí)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Implementace Randflake připravená pro produkční prostředí, obsahující mechanismus lease pro ID uzlu, je k dispozici na GitHubu.
Další úvahy
V této sekci probereme některé další úvahy pro implementaci Randflake ID.
Koordinace ID uzlů
Navrhujeme koordinaci ID uzlů založenou na lease.
Při tomto přístupu centrální koordinační služba přiřadí každému generátoru unikátní ID uzlu.
Toto ID uzlu se nepřiděluje znovu během období lease, aby byla zajištěna jedinečnost, což snižuje potřebu časté komunikace s koordinační službou.
Generátor držící lease může požádat o obnovení lease od koordinační služby, pokud je splněna podmínka obnovení.
Podmínka obnovení se vztahuje na soubor kritérií, která musí být splněna pro obnovení lease, jako je například to, že generátor je stále aktivní a vyžaduje ID uzlu.
Držitel lease je aktuálním držitelem rozsahu ID uzlů.
Lease je považováno za aktivní a nevypršelé, pokud je v rámci své platné časové lhůty.
Tímto způsobem můžeme snížit počet cest tam a zpět na jednu za období obnovení lease, čímž minimalizujeme latenci a zlepšujeme efektivitu v distribuovaných systémech.
Zmírnění problémů s chybnými hodinami
Služba lease musí při přidělování lease kontrolovat konzistenci časových razítek. Přiřazený čas zahájení lease musí být větší nebo roven času zahájení posledního lease.
Generátor by měl odmítnout požadavek, pokud je aktuální časové razítko menší než čas zahájení lease nebo větší než čas ukončení lease.
Tento postup je důležitý pro ochranu jedinečnosti generovaných ID, když se hodiny vrátí zpět. Například, pokud se hodiny vrátí zpět, může být přiděleno nové lease s časem zahájení dřívějším než u dříve přiděleného lease, což by potenciálně vedlo k generování duplicitních ID. Odmítáním požadavků s časovými razítky v rámci existujícího období lease tomuto scénáři předcházíme a udržujeme jedinečnost ID.
Uniformita distribuce ID
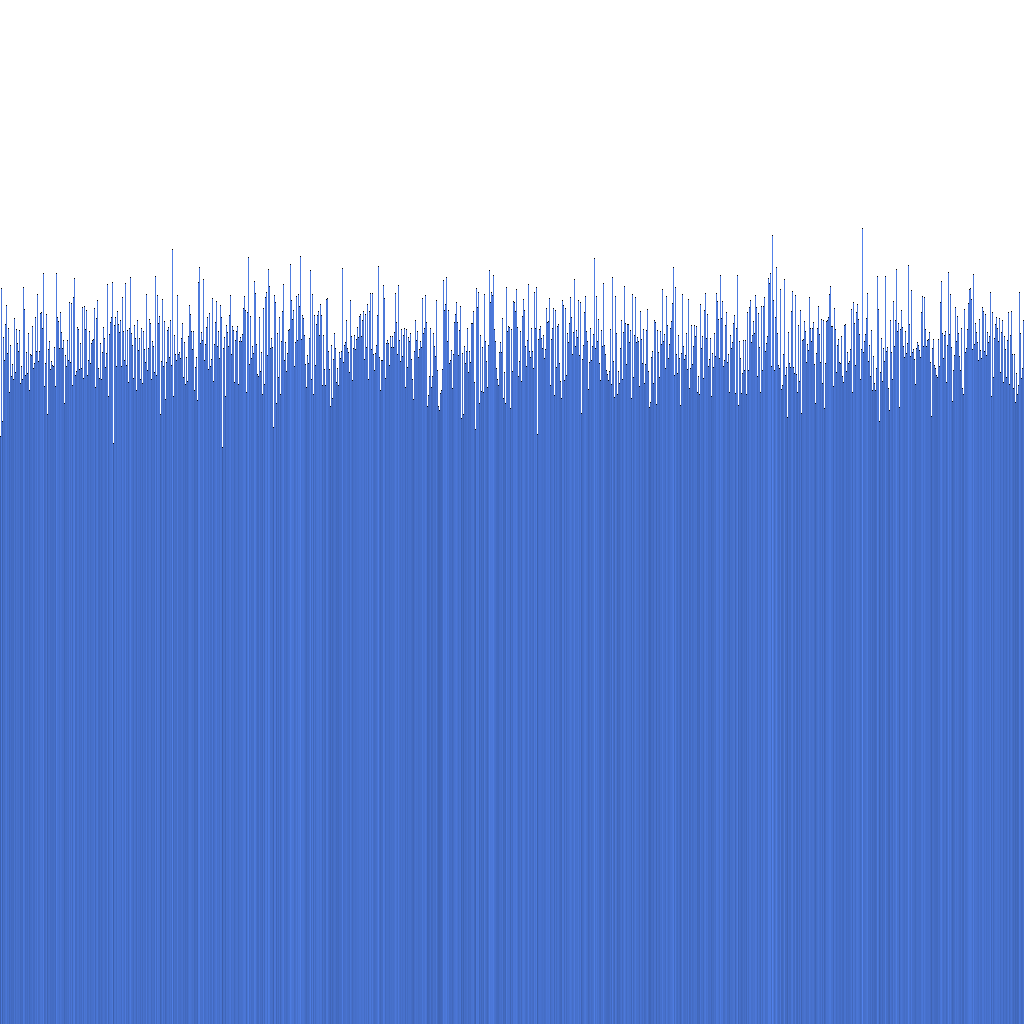
Na základě výše uvedeného histogramu je patrné, že distribuce generovaných Randflake ID je velmi uniformní. To naznačuje, že distribuce ID může být přímo použita jako sharding key.
Závěr
V tomto článku jsme představili Randflake, inovativní algoritmus pro generování ID, který kombinuje výhody Snowflake a Sparx64.
Doufáme, že vám tento článek poskytl komplexní pochopení Randflake a jeho implementace.
Úplný zdrojový kód Randflake naleznete na GitHubu.
Pokud máte jakékoli dotazy nebo návrhy, neváhejte nás kontaktovat. Hledáme také přispěvatele, kteří by pomohli vylepšit Randflake a implementovat jej v jiných programovacích jazycích.
Plánujeme vydat produkčně připravenou koordinační službu pro Randflake a Snowflake, která bude open-source na GitHubu. Sledujte aktuální informace!