Introduktion af Randflake ID: en distribueret, uniform, uforudsigelig, unik tilfældig ID-generator.
Forestil dig en situation, hvor vi skal generere unikke 64-bit tilfældige tal, og eksterne parter ikke må kunne forudsige det næste eller tidligere tal.
Her kan vi generere en 8-byte tilfældig værdi, kontrollere om den allerede eksisterer i databasen, og derefter gemme den, hvis den er unik.
Denne metode har imidlertid adskillige ulemper. Vi er nødt til at gemme hvert genereret tal i en database for at sikre unikhed. Kravet om mindst én tur-retur til databasen skaber latenstidsproblemer, især i et distribueret miljø, hvor skalerbarhed er afgørende.
For at løse disse problemer introducerer vi Randflake ID: en distribueret, ensartet, uforudsigelig, unik tilfældig ID-generator.
Hvordan fungerer Randflake ID?
Randflake ID er inspireret af Snowflake ID, den udbredte k-sorterede ID-genereringsmekanisme udviklet af X (tidligere Twitter).
Snowflake ID bruger det aktuelle tidsstempel, et node-ID og en lokal tæller til at generere en identifikator.
Vi udvidede denne tilgang yderligere til generering af tilfældige unikke ID'er og tilføjede et nyt hemmeligt nøgleelement.
Nøgleideen er at tilføje et blokchifferlag til den eksisterende unikke ID-generator for at opnå uigennemførlighed i at forudsige forholdet mellem tal.
Et blokchiffer er en grundlæggende kryptografisk funktion, der omdanner en fastlængde blok af klartekst til en blok af chiffertekst af samme længde. Denne transformation styres af en kryptografisk nøgle. Det karakteristiske ved et blokchiffer er dets reversibilitet: det skal være en en-til-en (bijektiv) funktion, der sikrer, at hvert unikt input svarer til et unikt output og omvendt. Denne egenskab er afgørende for dekryptering, da den tillader, at den originale klartekst kan gendannes fra chifferteksten, når den korrekte nøgle anvendes.
Ved at anvende et blokchiffer som en en-til-en funktion kan vi garantere, at hvert unikt input producerer et tilsvarende unikt output inden for det definerede område.
Struktur og designovervejelser
Med udgangspunkt i disse grundlæggende koncepter, lad os undersøge, hvordan Randflake ID implementerer disse ideer i praksis.
Randflake ID-strukturen inkluderer et 30-bit unix-tidsstempel med sekundpræcision, en 17-bit node-identifikator, en 17-bit lokal tæller og et 64-bit blokchiffer baseret på sparx64-algoritmen.
Her er nogle designbeslutninger:
Nogle VM-instanser i Google Cloud Platform kan synkronisere uret med 0,2 ms præcision, men dette nøjagtighedsniveau er ikke tilgængeligt på offentligt internet eller andre cloud-udbydere.
Vi valgte en sekundpræcision, fordi vi effektivt kan synkronisere uret mellem noder kun inden for få millisekund-opløsninger.
17-bit node-identifikator tillader 131072 individuelle generatorer på samme tid, som kan tildeles per-proces, per-kerne, per-tråd måde.
I systemer med høj gennemløb kan en 17-bit lokal tæller være utilstrækkelig. For at matche gennemløbet kan vi tildele flere generatorer, hver med et særskilt node-ID, til at arbejde i en enkelt proces eller tråd.
Vi anvendte sparx64 som et 64-bit blokchiffer, et moderne letvægts ARX-baseret blokchiffer.
Randflake ID'er tilbyder intern sporbarhed, der kun afslører deres oprindelses node-ID og tidsstempel for dem, der besidder den hemmelige nøgle.
Teoretisk maksimal gennemløb er 17.179.869.184 ID/s, hvilket er tilstrækkeligt for de fleste globale applikationer.
Pseudokode for Randflake ID-generering
For yderligere at illustrere Randflake ID-genereringsprocessen giver den følgende Python-pseudokode en forenklet implementering:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Konstanter
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Søndag, 27. oktober 2024 3:33:20 AM UTC
7
8# Bitallokering
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bit til tidsstempel (levetid på 34 år)
10RANDFLAKE_NODE_BITS = 17 # 17 bit til node-ID (maks. 131072 noder)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bit til sekvens (maks. 131072 sekvenser)
12
13# Afledte konstanter
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
En produktionsklar implementering af Randflake, der inkluderer en node ID lease-mekanisme, er tilgængelig på GitHub.
Andre overvejelser
I dette afsnit vil vi diskutere nogle yderligere overvejelser for implementering af Randflake ID.
Koordinering af node-ID
Vi foreslår lease-baseret koordinering af node-ID.
I denne tilgang tildeler en central koordinationstjeneste et unikt node-ID til hver generator.
Dette node-ID gentildeles ikke i leaseperioden for at sikre unikhed, hvilket reducerer behovet for hyppig kommunikation med koordinationstjenesten.
Generatoren, der holder leasen, kan anmode om en fornyelse af leasen fra koordinationstjenesten, hvis fornyelsesbetingelsen er opfyldt.
Fornyelsesbetingelsen refererer til et sæt kriterier, der skal opfyldes for at leasen kan fornyes, såsom at generatoren stadig er aktiv og kræver node-ID'et.
Leaseholderen er den nuværende indehaver af node-ID-området.
Leasen betragtes som aktiv og ikke udløbet, hvis den er inden for dens gyldige tidsperiode.
På denne måde kan vi reducere tur-retur-rejser til én per leasefornyelsesperiode, hvilket minimerer latenstid og forbedrer effektiviteten i distribuerede systemer.
Afbødning mod fejlbehæftet ur
Leasetjenesten skal kontrollere tidsstempelkonsistensen ved tildeling af en lease. Den tildelte lease-starttid skal være større end eller lig med den sidste lease-starttid.
Generatoren bør afvise anmodningen, hvis det aktuelle tidsstempel er mindre end lease-starttiden eller større end lease-sluttiden.
Denne procedure er vigtig for at beskytte unikheden af genererede ID'er, når uret springer tilbage. For eksempel, hvis et ur springer tilbage, kan en ny lease tildeles med en starttid tidligere end en tidligere tildelt lease, hvilket potentielt kan føre til generering af duplikerede ID'er. Ved at afvise anmodninger med tidsstempler inden for en eksisterende leaseperiode forhindrer vi dette scenarie og opretholder ID'ernes unikhed.
Ensartethed i ID-distribution
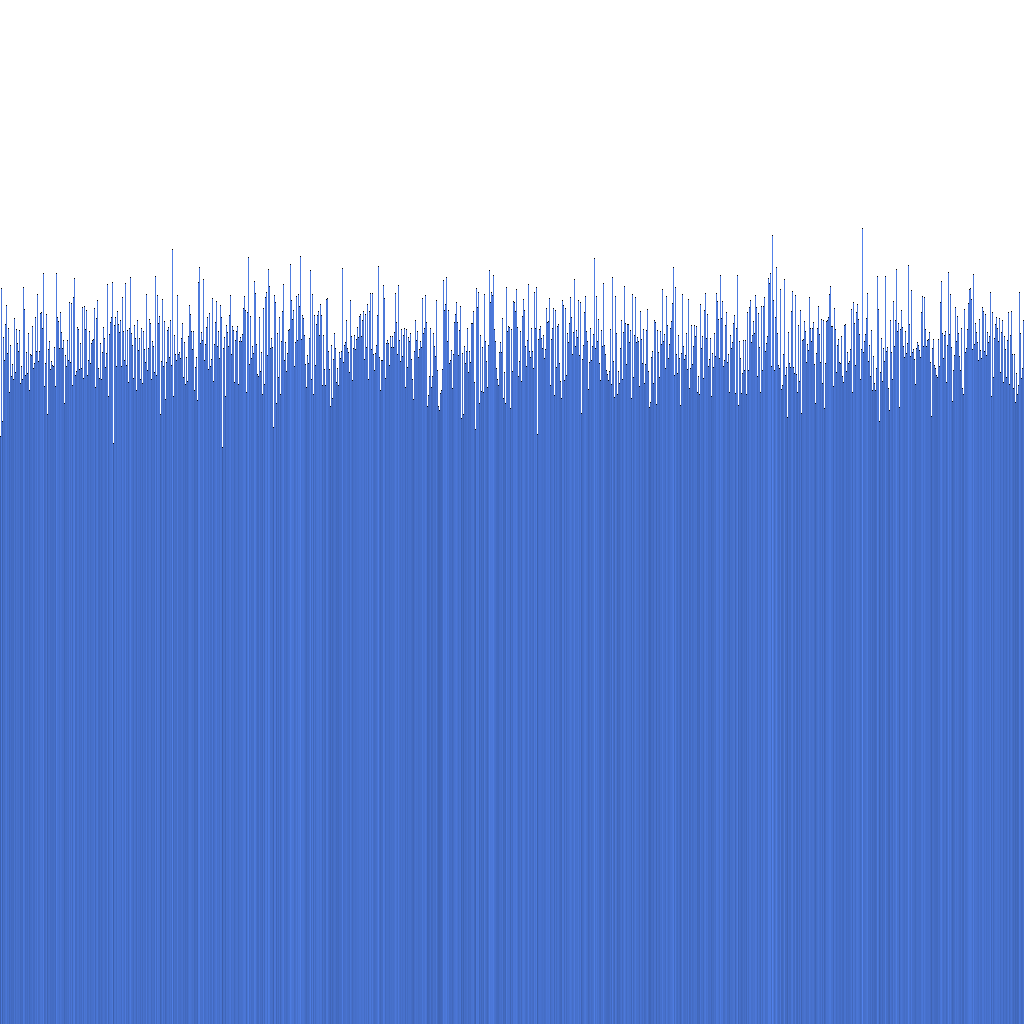
Baseret på histogrammet ovenfor kan vi se, at fordelingen af genererede Randflake ID'er er meget ensartet. Dette tyder på, at ID-fordelingen kan bruges direkte som en sharding key.
Konklusion
I denne artikel introducerede vi Randflake, en ny ID-genereringsalgoritme, der kombinerer fordelene ved Snowflake og Sparx64.
Vi håber, at denne artikel har givet dig en omfattende forståelse af Randflake og dens implementering.
Du kan finde den fulde kildekode til Randflake på GitHub.
Hvis du har spørgsmål eller forslag, er du velkommen til at kontakte os. Vi søger også bidragydere til at hjælpe med at forbedre Randflake og implementere det i andre programmeringssprog.
Vi planlægger at frigive en produktionsklar koordinationstjeneste for Randflake og Snowflake, som vil blive open-sourced på GitHub. Følg med for opdateringer!