Einführung von Randflake ID: einem verteilten, einheitlichen, unvorhersehbaren, einzigartigen Zufalls-ID-Generator.
Betrachten Sie eine Situation, in der wir eindeutige 64-Bit-Zufallszahlen generieren müssen und externe Parteien nicht in der Lage sein sollen, die nächste oder vorherige Zahl vorherzusagen.
Hier können wir einen 8-Byte-Zufallswert generieren, prüfen, ob er bereits in der Datenbank existiert, und ihn dann speichern, wenn er eindeutig ist.
Diese Methode weist jedoch mehrere Nachteile auf. Wir müssen jede generierte Zahl in einer Datenbank speichern, um die Eindeutigkeit zu gewährleisten. Die Notwendigkeit von mindestens einem Roundtrip zur Datenbank führt zu Latenzproblemen, insbesondere in einer verteilten Umgebung, wo Skalierbarkeit entscheidend ist.
Um diese Probleme zu lösen, führen wir Randflake ID ein: einen verteilten, einheitlichen, unvorhersehbaren, eindeutigen Zufalls-ID-Generator.
Wie funktioniert Randflake ID?
Randflake ID ist von Snowflake ID inspiriert, dem weit verbreiteten k-sortierten ID-Generierungsmechanismus, der von X (ehemals Twitter) entwickelt wurde.
Snowflake ID verwendet den aktuellen Zeitstempel, eine Knoten-ID und einen lokalen Zähler, um einen Bezeichner zu generieren.
Wir haben diesen Ansatz für die Generierung zufälliger eindeutiger IDs erweitert und ein neues Geheimschlüsselelement hinzugefügt.
Die Kernidee besteht darin, eine Blockchiffre-Schicht zu dem bestehenden eindeutigen ID-Generator hinzuzufügen, um die Vorhersagbarkeit der Beziehung zwischen Zahlen unmöglich zu machen.
Eine Blockchiffre ist eine fundamentale kryptographische Funktion, die einen Block fester Länge von Klartext in einen Block von Chiffretext derselben Länge umwandelt. Diese Transformation wird durch einen kryptographischen Schlüssel gesteuert. Das unterscheidende Merkmal einer Blockchiffre ist ihre Reversibilität: Sie muss eine Eins-zu-Eins (bijektive) Funktion sein, die sicherstellt, dass jede eindeutige Eingabe einer eindeutigen Ausgabe entspricht und umgekehrt. Diese Eigenschaft ist entscheidend für die Entschlüsselung, da sie es ermöglicht, den ursprünglichen Klartext aus dem Chiffretext wiederherzustellen, wenn der korrekte Schlüssel angewendet wird.
Durch den Einsatz einer Blockchiffre als Eins-zu-Eins-Funktion können wir garantieren, dass jede eindeutige Eingabe eine entsprechende eindeutige Ausgabe innerhalb des definierten Bereichs erzeugt.
Die Struktur und Designüberlegungen
Aufbauend auf diesen grundlegenden Konzepten wollen wir untersuchen, wie Randflake ID diese Ideen in der Praxis umsetzt.
Die Randflake ID-Struktur umfasst einen 30-Bit-Unix-Zeitstempel mit Sekundengenauigkeit, einen 17-Bit-Knotenbezeichner, einen 17-Bit-lokalen Zähler und eine 64-Bit-Blockchiffre, die auf dem sparx64-Algorithmus basiert.
Hier sind einige Designentscheidungen:
Einige VM-Instanzen in der Google Cloud Platform können die Uhr mit einer Genauigkeit von 0,2 ms synchronisieren, aber dieses Genauigkeitsniveau ist im öffentlichen Internet oder bei anderen Cloud-Anbietern nicht verfügbar.
Wir haben eine Sekundengenauigkeit gewählt, da wir die Uhr zwischen Knoten nur innerhalb weniger Millisekunden effektiv synchronisieren können.
Ein 17-Bit-Knotenbezeichner ermöglicht 131072 einzelne Generatoren gleichzeitig, die pro Prozess, pro Kern oder pro Thread zugewiesen werden können.
In Systemen mit hohem Durchsatz kann ein 17-Bit-Lokalzähler unzureichend sein. Um den Durchsatz zu erreichen, können wir einem einzelnen Prozess oder Thread mehrere Generatoren zuweisen, von denen jeder eine eindeutige Knoten-ID besitzt.
Wir haben sparx64 als 64-Bit-Blockchiffre übernommen, eine moderne, leichtgewichtige ARX-basierte Blockchiffre.
Randflake IDs bieten eine interne Rückverfolgbarkeit, die ihre Ursprungsknoten-ID und den Zeitstempel nur jenen offenbart, die den geheimen Schlüssel besitzen.
Der theoretische maximale Durchsatz beträgt 17.179.869.184 ID/s, was für die meisten Anwendungen im globalen Maßstab ausreichend ist.
Pseudocode der Randflake ID-Generierung
Um den Randflake ID-Generierungsprozess weiter zu veranschaulichen, bietet der folgende Python-Pseudocode eine vereinfachte Implementierung:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Sonntag, 27. Oktober 2024, 03:33:20 Uhr UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 Bits für Zeitstempel (Lebensdauer von 34 Jahren)
10RANDFLAKE_NODE_BITS = 17 # 17 Bits für Knoten-ID (max. 131072 Knoten)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 Bits für Sequenz (max. 131072 Sequenzen)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Eine produktionsreife Implementierung von Randflake, die einen Node ID Lease-Mechanismus bietet, ist auf GitHub verfügbar.
Weitere Überlegungen
In diesem Abschnitt werden wir einige zusätzliche Überlegungen zur Implementierung von Randflake ID diskutieren.
Koordination der Knoten-ID
Wir schlagen eine lease-basierte Koordinierung der Knoten-ID vor.
Bei diesem Ansatz weist ein zentraler Koordinierungsdienst jedem Generator eine eindeutige Knoten-ID zu.
Diese Knoten-ID wird während der Leasingperiode nicht neu zugewiesen, um die Eindeutigkeit zu gewährleisten, wodurch die Notwendigkeit häufiger Kommunikation mit dem Koordinierungsdienst reduziert wird.
Der Generator, der die Lease hält, kann eine Verlängerung der Lease beim Koordinierungsdienst beantragen, wenn die Verlängerungsbedingung erfüllt ist.
Die Verlängerungsbedingung bezieht sich auf eine Reihe von Kriterien, die erfüllt sein müssen, damit die Lease verlängert wird, z. B. dass der Generator noch aktiv ist und die Knoten-ID benötigt.
Der Leaseholder ist der aktuelle Inhaber des Knoten-ID-Bereichs.
Die Lease gilt als aktiv und nicht abgelaufen, wenn sie sich innerhalb ihres gültigen Zeitraums befindet.
Auf diese Weise können wir die Roundtrips auf einen pro Lease-Verlängerungszeitraum reduzieren, wodurch die Latenz minimiert und die Effizienz in verteilten Systemen verbessert wird.
Maßnahmen gegen fehlerhafte Uhr
Der Lease-Dienst muss bei der Zuweisung einer Lease die Zeitstempelkonsistenz überprüfen. Die zugewiesene Startzeit der Lease muss größer oder gleich der letzten Startzeit der Lease sein.
Der Generator sollte die Anfrage ablehnen, wenn der aktuelle Zeitstempel kleiner als die Startzeit der Lease oder größer als die Endzeit der Lease ist.
Dieses Verfahren ist wichtig, um die Einzigartigkeit generierter IDs zu schützen, wenn die Uhr zurückspringt. Wenn beispielsweise eine Uhr zurückspringt, könnte eine neue Lease mit einer Startzeit zugewiesen werden, die vor einer zuvor zugewiesenen Lease liegt, was möglicherweise zur Generierung doppelter IDs führen könnte. Indem wir Anfragen mit Zeitstempeln innerhalb einer bestehenden Lease-Periode ablehnen, verhindern wir dieses Szenario und erhalten die Einzigartigkeit der IDs.
Gleichmäßigkeit der ID-Verteilung
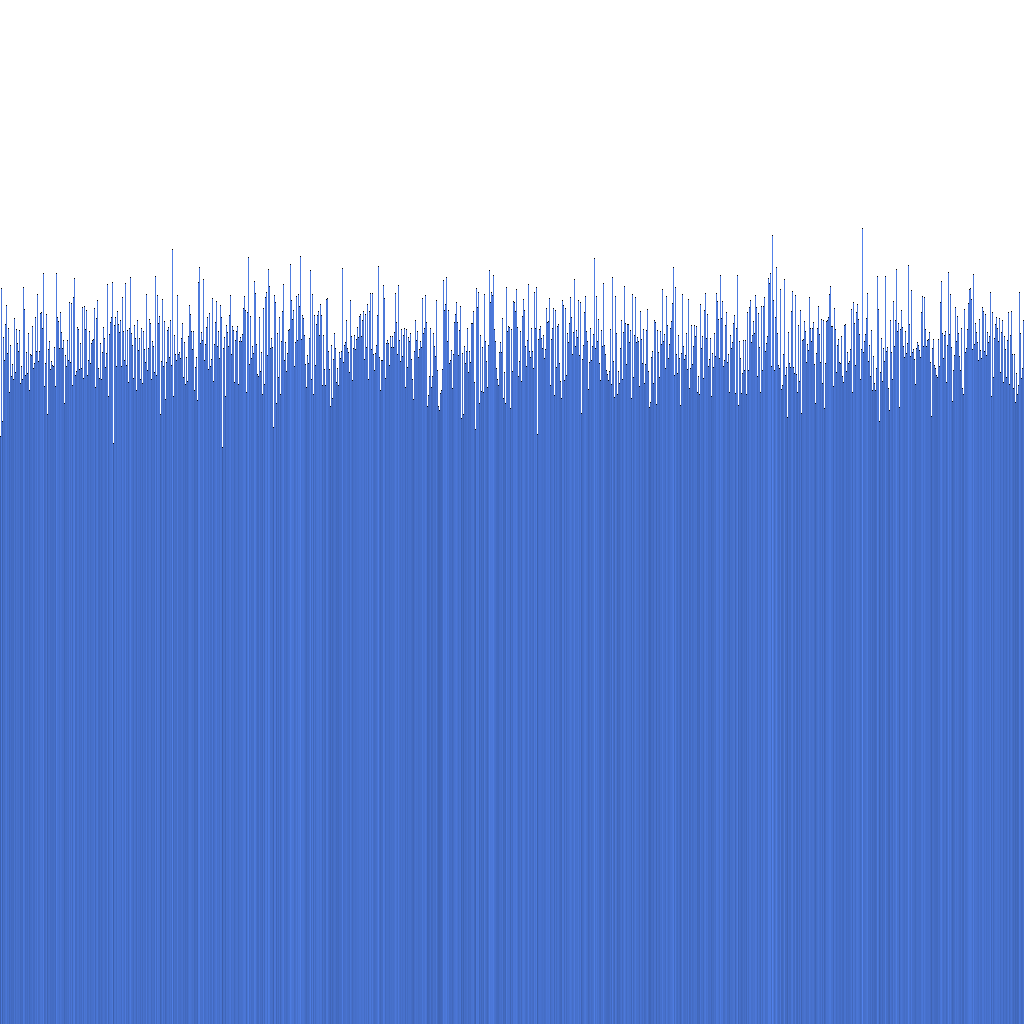
Basierend auf dem obigen Histogramm können wir sehen, dass die Verteilung der generierten Randflake IDs sehr gleichmäßig ist. Dies deutet darauf hin, dass die ID-Verteilung direkt als Sharding-Schlüssel verwendet werden kann.
Fazit
In diesem Artikel haben wir Randflake vorgestellt, einen neuartigen ID-Generierungsalgorithmus, der die Vorteile von Snowflake und Sparx64 kombiniert.
Wir hoffen, dass dieser Artikel Ihnen ein umfassendes Verständnis von Randflake und seiner Implementierung vermittelt hat.
Den vollständigen Quellcode für Randflake finden Sie auf GitHub.
Wenn Sie Fragen oder Anregungen haben, zögern Sie bitte nicht, uns zu kontaktieren. Wir suchen auch Mitwirkende, die Randflake verbessern und in anderen Programmiersprachen implementieren möchten.
Wir planen, einen produktionsreifen Koordinierungsdienst für Randflake und Snowflake zu veröffentlichen, der als Open Source auf GitHub verfügbar sein wird. Bleiben Sie dran für Updates!