Presentamos Randflake ID: un generador de ID aleatorio distribuido, uniforme, impredecible y único.
Considere una situación en la que necesitamos generar números aleatorios únicos de 64 bits, y terceros no deberían poder predecir el número siguiente o el anterior.
Aquí, podemos generar un valor aleatorio de 8 bytes, verificar si ya existe en la base de datos y luego almacenarlo si es único.
Sin embargo, este método tiene varios inconvenientes. Tenemos que almacenar cada número generado en una base de datos para asegurar su unicidad. El requisito de al menos un viaje de ida y vuelta a la base de datos crea problemas de latencia, particularmente en un entorno distribuido donde la escalabilidad es crucial.
Para resolver estos problemas, presentamos Randflake ID: un generador de ID aleatorio distribuido, uniforme, impredecible y único.
¿Cómo funciona Randflake ID?
Randflake ID está inspirado en Snowflake ID, el mecanismo de generación de ID k-ordenado ampliamente utilizado desarrollado por X (anteriormente Twitter).
Snowflake ID utiliza la marca de tiempo actual, un ID de nodo y un contador local para generar un identificador.
Ampliamos este enfoque para la generación de ID únicos aleatorios y añadimos un nuevo elemento de clave secreta.
La idea clave es añadir una capa de cifrado de bloque al generador de ID único existente para lograr la inviabilidad en la predicción de la relación entre números.
Un cifrado de bloque es una función criptográfica fundamental que transforma un bloque de texto plano de longitud fija en un bloque de texto cifrado de la misma longitud. Esta transformación está gobernada por una clave criptográfica. La característica distintiva de un cifrado de bloque es su reversibilidad: debe ser una función uno a uno (biyectiva), asegurando que cada entrada única corresponde a una salida única, y viceversa. Esta propiedad es crucial para el descifrado, permitiendo recuperar el texto plano original del texto cifrado cuando se aplica la clave correcta.
Al emplear un cifrado de bloque como una función uno a uno, podemos garantizar que cada entrada única produce una salida única correspondiente dentro del rango definido.
La estructura y consideraciones de diseño
Basándonos en estos conceptos fundamentales, examinemos cómo Randflake ID implementa estas ideas en la práctica.
La estructura de Randflake ID incluye una marca de tiempo Unix de 30 bits con precisión de segundo, un identificador de nodo de 17 bits, un contador local de 17 bits y un cifrado de bloque de 64 bits basado en el algoritmo sparx64.
Aquí están algunas decisiones de diseño:
Algunas instancias de VM en Google Cloud Platform pueden sincronizar el reloj con una precisión de 0.2ms, pero ese nivel de exactitud no está disponible en la internet pública o en otros proveedores de la nube.
Seleccionamos una precisión de segundo porque podemos sincronizar eficazmente el reloj entre nodos solo con una resolución de unos pocos milisegundos.
El identificador de nodo de 17 bits permite 131072 generadores individuales al mismo tiempo, que pueden asignarse por proceso, por núcleo o por hilo.
En sistemas de alto rendimiento, un contador local de 17 bits puede ser insuficiente. Para igualar el rendimiento, podemos asignar múltiples generadores, cada uno con un ID de nodo distinto, para trabajar en un solo proceso o hilo.
Adoptamos sparx64 como un cifrado de bloque de 64 bits, un moderno cifrado de bloque ligero basado en ARX.
Los Randflake IDs ofrecen trazabilidad interna, revelando su ID de nodo de origen y su marca de tiempo solo a aquellos que poseen la clave secreta.
El rendimiento teórico máximo es de 17,179,869,184 ID/s, lo cual es suficiente para la mayoría de las aplicaciones a escala global.
Pseudocódigo de la generación de Randflake ID
Para ilustrar aún más el proceso de generación de Randflake ID, el siguiente pseudocódigo Python proporciona una implementación simplificada:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Sunday, October 27, 2024 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bits for timestamp (lifetime of 34 years)
10RANDFLAKE_NODE_BITS = 17 # 17 bits for node id (max 131072 nodes)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bits for sequence (max 131072 sequences)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Una implementación de Randflake lista para producción, con un mecanismo de arrendamiento de ID de nodo, está disponible en GitHub.
Otras consideraciones
En esta sección, discutiremos algunas consideraciones adicionales para implementar Randflake ID.
Coordinación de ID de nodo
Sugerimos la coordinación de ID de nodo basada en arrendamiento.
En este enfoque, un servicio de coordinación central asigna un ID de nodo único a cada generador.
Este ID de nodo no se reasigna durante el período de arrendamiento para asegurar la unicidad, reduciendo la necesidad de comunicación frecuente con el servicio de coordinación.
El generador que posee el arrendamiento puede solicitar una renovación del arrendamiento al servicio de coordinación si se cumple la condición de renovación.
La condición de renovación se refiere a un conjunto de criterios que deben satisfacerse para que el arrendamiento sea renovado, como que el generador siga activo y requiera el ID de nodo.
El titular del arrendamiento es el actual poseedor del rango de ID de nodo.
El arrendamiento se considera activo y no vencido si está dentro de su período de tiempo válido.
De esta manera, podemos reducir los viajes de ida y vuelta a uno por período de renovación de arrendamiento, minimizando la latencia y mejorando la eficiencia en sistemas distribuidos.
Mitigación contra relojes defectuosos
El servicio de arrendamiento debe verificar la consistencia de la marca de tiempo al asignar un arrendamiento. La hora de inicio del arrendamiento asignado debe ser mayor o igual que la hora de inicio del último arrendamiento.
El generador debe rechazar la solicitud si la marca de tiempo actual es menor que la hora de inicio del arrendamiento o mayor que la hora de finalización del arrendamiento.
Este procedimiento es importante para proteger la unicidad de los ID generados cuando el reloj retrocede. Por ejemplo, si un reloj retrocede, se podría asignar un nuevo arrendamiento con una hora de inicio anterior a un arrendamiento asignado previamente, lo que podría conducir a la generación de ID duplicados. Al rechazar solicitudes con marcas de tiempo dentro de un período de arrendamiento existente, prevenimos este escenario y mantenemos la unicidad de los ID.
Uniformidad de la distribución de ID
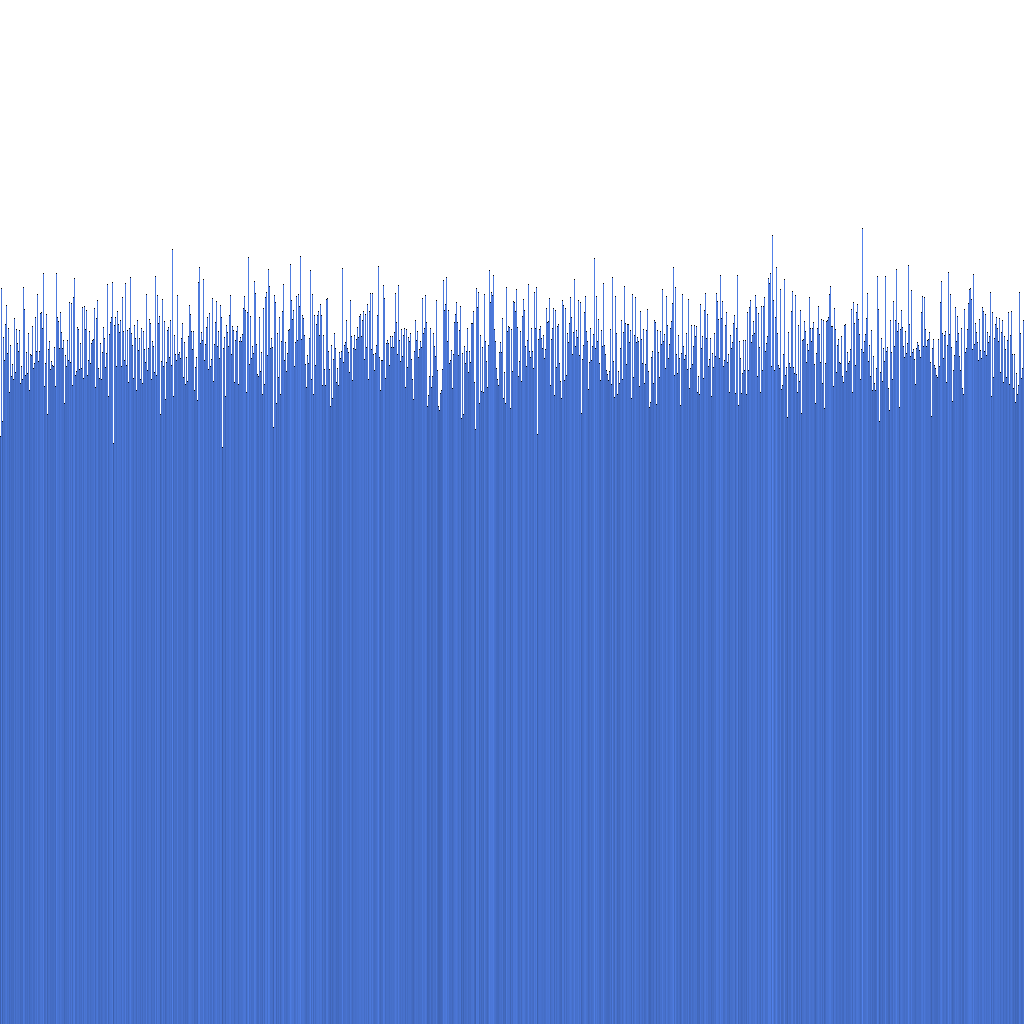
Basándonos en el histograma anterior, podemos observar que la distribución de los Randflake IDs generados es muy uniforme. Esto sugiere que la distribución de ID puede utilizarse directamente como una clave de sharding.
Conclusión
En este artículo, presentamos Randflake, un algoritmo novedoso de generación de ID que combina las ventajas de Snowflake y Sparx64.
Esperamos que este artículo le haya proporcionado una comprensión exhaustiva de Randflake y su implementación.
Puede encontrar el código fuente completo de Randflake en GitHub.
Si tiene alguna pregunta o sugerencia, no dude en ponerse en contacto. También estamos buscando colaboradores para ayudar a mejorar Randflake e implementarlo en otros lenguajes de programación.
Estamos planeando lanzar un servicio de coordinación listo para producción para Randflake y Snowflake, que será de código abierto en GitHub. ¡Manténgase atento a las actualizaciones!