Améliorer la réactivité avec le cache côté client Redis
Qu'est-ce que Redis ?
Je suppose que peu de gens ne connaissent pas Redis. Cependant, si je devais le mentionner brièvement avec quelques caractéristiques, on pourrait le résumer comme suit :
- Les opérations sont exécutées en monothread, ce qui confère à toutes les opérations une atomicité.
- Les données sont stockées et traitées en mémoire, ce qui rend toutes les opérations rapides.
- Redis peut enregistrer un WAL (Write-Ahead Log) selon les options, permettant une sauvegarde et une récupération rapides de l'état le plus récent.
- Il prend en charge plusieurs types tels que Set, Hash, Bit, List, offrant une productivité élevée.
- Il dispose d'une grande communauté, permettant de partager diverses expériences, problèmes et solutions.
- Il a été développé et exploité pendant longtemps, ce qui lui confère une stabilité fiable.
Passons au sujet principal
Imaginez-vous ?
Que se passerait-il si le cache de votre service remplissait les deux conditions suivantes ?
- Vous devez fournir des données fréquemment consultées à l'utilisateur dans leur état le plus récent, mais les mises à jour sont irrégulières, nécessitant des rafraîchissements fréquents du cache.
- Les mises à jour ne sont pas effectuées, mais les mêmes données de cache doivent être consultées fréquemment.
Le premier cas peut être illustré par les classements de popularité en temps réel d'un centre commercial. Si le classement de popularité en temps réel d'un centre commercial est stocké sous forme de sorted set, il serait inefficace que Redis le lise chaque fois qu'un utilisateur accède à la page principale. Dans le second cas, pour les données de taux de change, même si les données sont actualisées toutes les 10 minutes environ, les consultations réelles sont très fréquentes. En particulier, les taux de change Won-Dollar, Won-Yen et Won-Yuan sont consultés très fréquemment dans le cache. Dans ces cas, il serait plus efficace que le serveur API dispose d'un cache local séparé et rafraîchisse les données en interrogeant Redis à nouveau lorsque les données changent.
Alors, comment peut-on implémenter un tel comportement dans une architecture Base de données - Redis - Serveur API ?
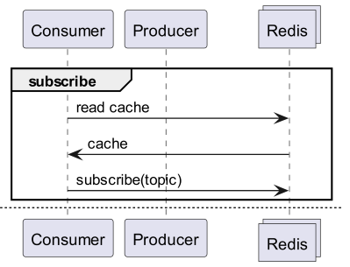
N'est-ce pas possible avec Redis PubSub ?
Lors de l'utilisation du cache, abonnez-vous à un canal qui peut recevoir des notifications de mise à jour !
- Il faudrait alors créer une logique pour envoyer des messages lors des mises à jour.
- L'opération supplémentaire due à PubSub affecte les performances.
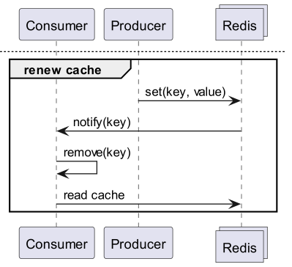
Et si Redis détectait les changements ?
En utilisant Keyspace Notification pour recevoir des notifications de commande pour une clé spécifique ?
- Il y a la complexité de devoir stocker et partager à l'avance les clés et les commandes utilisées pour la mise à jour.
- Par exemple, pour certaines clés, un simple Set est une commande de mise à jour, tandis que pour d'autres, LPush, RPush, SAdd ou SRem sont des commandes de mise à jour, ce qui rend la situation complexe.
- Cela augmente considérablement le risque d'erreurs de communication et d'erreurs humaines lors du codage pendant le processus de développement.
En utilisant Keyevent Notification pour recevoir des notifications au niveau de la commande ?
- Il est nécessaire de s'abonner à toutes les commandes utilisées pour la mise à jour. Un filtrage approprié est nécessaire pour les clés entrantes.
- Par exemple, il est fort probable que le client n'ait pas de cache local pour certaines des clés reçues via Del.
- Cela peut entraîner un gaspillage inutile de ressources.
D'où la nécessité de l'Invalidation Message !
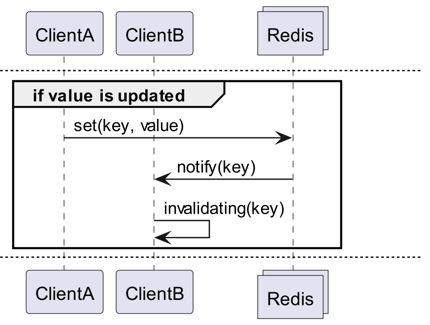
Qu'est-ce qu'un Invalidation Message ?
Les Invalidation Messages sont un concept introduit avec Redis 6.0, faisant partie du Server Assisted Client-Side Cache. Un Invalidation Message est transmis selon le flux suivant :
- Supposons que ClientB a déjà lu la clé une fois.
- ClientA définit une nouvelle valeur pour cette clé.
- Redis détecte le changement et publie un Invalidation Message à ClientB pour lui indiquer de supprimer le cache.
- ClientB reçoit ce message et prend les mesures appropriées.
Comment l'utiliser
Structure de fonctionnement de base
Un client connecté à Redis exécute CLIENT TRACKING ON REDIRECT <client-id> pour recevoir les messages d'invalidation. Le client qui doit recevoir les messages s'abonne ensuite à SUBSCRIBE __redis__:invalidate pour les recevoir.
default tracking
1# client 1
2> SET a 100
1# client 3
2> CLIENT ID
312
4> SUBSCRIBE __redis__:invalidate
51) "subscribe"
62) "__redis__:invalidate"
73) (integer) 1
1# client 2
2> CLIENT TRACKING ON REDIRECT 12
3> GET a # tracking
1# client 1
2> SET a 200
1# client 3
21) "message"
32) "__redis__:invalidate"
43) 1) "a"
broadcasting tracking
1# client 3
2> CLIENT ID
312
4> SUBSCRIBE __redis__:invalidate
51) "subscribe"
62) "__redis__:invalidate"
73) (integer) 1
1# client 2
2CLIENT TRACKING ON BCAST PREFIX cache: REDIRECT 12
1# client 1
2> SET cache:name "Alice"
3> SET cache:age 26
1# client 3
21) "message"
32) "__redis__:invalidate"
43) 1) "cache:name"
51) "message"
62) "__redis__:invalidate"
73) 1) "cache:age"
Implémentation ! Implémentation ! Implémentation !
Redigo + Ristretto
Une simple explication comme celle-ci peut être ambiguë quant à la manière de l'utiliser dans le code. Nous allons donc d'abord le configurer simplement avec redigo et ristretto.
Installez d'abord les deux dépendances.
github.com/gomodule/redigogithub.com/dgraph-io/ristretto
1package main
2
3import (
4 "context"
5 "fmt"
6 "log/slog"
7 "time"
8
9 "github.com/dgraph-io/ristretto"
10 "github.com/gomodule/redigo/redis"
11)
12
13type RedisClient struct {
14 conn redis.Conn
15 cache *ristretto.Cache[string, any]
16 addr string
17}
18
19func NewRedisClient(addr string) (*RedisClient, error) {
20 cache, err := ristretto.NewCache(&ristretto.Config[string, any]{
21 NumCounters: 1e7, // nombre de clés dont la fréquence est suivie (10M).
22 MaxCost: 1 << 30, // coût maximal du cache (1GB).
23 BufferItems: 64, // nombre de clés par tampon Get.
24 })
25 if err != nil {
26 return nil, fmt.Errorf("failed to generate cache: %w", err)
27 }
28
29 conn, err := redis.Dial("tcp", addr)
30 if err != nil {
31 return nil, fmt.Errorf("failed to connect to redis: %w", err)
32 }
33
34 return &RedisClient{
35 conn: conn,
36 cache: cache,
37 addr: addr,
38 }, nil
39}
40
41func (r *RedisClient) Close() error {
42 err := r.conn.Close()
43 if err != nil {
44 return fmt.Errorf("failed to close redis connection: %w", err)
45 }
46
47 return nil
48}
Nous créons d'abord un RedisClient simple qui inclut ristretto et redigo.
1func (r *RedisClient) Tracking(ctx context.Context) error {
2 psc, err := redis.Dial("tcp", r.addr)
3 if err != nil {
4 return fmt.Errorf("failed to connect to redis: %w", err)
5 }
6
7 clientId, err := redis.Int64(psc.Do("CLIENT", "ID"))
8 if err != nil {
9 return fmt.Errorf("failed to get client id: %w", err)
10 }
11 slog.Info("client id", "id", clientId)
12
13 subscriptionResult, err := redis.String(r.conn.Do("CLIENT", "TRACKING", "ON", "REDIRECT", clientId))
14 if err != nil {
15 return fmt.Errorf("failed to enable tracking: %w", err)
16 }
17 slog.Info("subscription result", "result", subscriptionResult)
18
19 if err := psc.Send("SUBSCRIBE", "__redis__:invalidate"); err != nil {
20 return fmt.Errorf("failed to subscribe: %w", err)
21 }
22 psc.Flush()
23
24 for {
25 msg, err := psc.Receive()
26 if err != nil {
27 return fmt.Errorf("failed to receive message: %w", err)
28 }
29
30 switch msg := msg.(type) {
31 case redis.Message:
32 slog.Info("received message", "channel", msg.Channel, "data", msg.Data)
33 key := string(msg.Data)
34 r.cache.Del(key)
35 case redis.Subscription:
36 slog.Info("subscription", "kind", msg.Kind, "channel", msg.Channel, "count", msg.Count)
37 case error:
38 return fmt.Errorf("error: %w", msg)
39 case []interface{}:
40 if len(msg) != 3 || string(msg[0].([]byte)) != "message" || string(msg[1].([]byte)) != "__redis__:invalidate" {
41 slog.Warn("unexpected message", "message", msg)
42 continue
43 }
44
45 contents := msg[2].([]interface{})
46 keys := make([]string, len(contents))
47 for i, key := range contents {
48 keys[i] = string(key.([]byte))
49 r.cache.Del(keys[i])
50 }
51 slog.Info("received invalidation message", "keys", keys)
52 default:
53 slog.Warn("unexpected message", "type", fmt.Sprintf("%T", msg))
54 }
55 }
56}
Le code est un peu complexe.
- Pour le Tracking, une connexion supplémentaire est établie. Cette mesure vise à éviter que PubSub n'interfère avec d'autres opérations.
- L'ID de la connexion ajoutée est récupéré, et le Tracking est redirigé vers cette connexion depuis la connexion qui interrogera les données.
- Ensuite, les messages d'invalidation sont souscrits.
- Le code de traitement de la souscription est un peu complexe. Comme redigo ne gère pas le parsing des messages d'invalidation, il est nécessaire de recevoir la réponse avant le parsing et de la traiter.
1func (r *RedisClient) Get(key string) (any, error) {
2 val, found := r.cache.Get(key)
3 if found {
4 switch v := val.(type) {
5 case int64:
6 slog.Info("cache hit", "key", key)
7 return v, nil
8 default:
9 slog.Warn("unexpected type", "type", fmt.Sprintf("%T", v))
10 }
11 }
12 slog.Info("cache miss", "key", key)
13
14 val, err := redis.Int64(r.conn.Do("GET", key))
15 if err != nil {
16 return nil, fmt.Errorf("failed to get key: %w", err)
17 }
18
19 r.cache.SetWithTTL(key, val, 1, 10*time.Second)
20 return val, nil
21}
Le message Get interroge d'abord Ristretto, et s'il n'est pas trouvé, il le récupère depuis Redis.
1package main
2
3import (
4 "context"
5 "log/slog"
6 "os"
7 "os/signal"
8 "time"
9)
10
11func main() {
12 ctx, cancel := signal.NotifyContext(context.Background(), os.Interrupt)
13 defer cancel()
14
15 client, err := NewRedisClient("localhost:6379")
16 if err != nil {
17 panic(err)
18 }
19 defer client.Close()
20
21 go func() {
22 if err := client.Tracking(ctx); err != nil {
23 slog.Error("failed to track invalidation message", "error", err)
24 }
25 }()
26
27 ticker := time.NewTicker(1 * time.Second)
28 defer ticker.Stop()
29 done := ctx.Done()
30
31 for {
32 select {
33 case <-done:
34 slog.Info("shutting down")
35 return
36 case <-ticker.C:
37 v, err := client.Get("key")
38 if err != nil {
39 slog.Error("failed to get key", "error", err)
40 return
41 }
42 slog.Info("got key", "value", v)
43 }
44 }
45}
Le code de test est comme ci-dessus. Si vous le testez, vous pourrez constater que la valeur est mise à jour chaque fois que les données sont modifiées dans Redis.
Mais c'est trop complexe. Surtout, pour l'étendre à un cluster, il est inévitable d'activer le Tracking pour tous les maîtres ou réplicas.
Rueidis
Pour les utilisateurs de Go, nous avons rueidis, la bibliothèque la plus moderne et la plus avancée. Nous allons écrire du code utilisant le cache côté client assisté par le serveur dans un environnement de cluster Redis avec rueidis.
Tout d'abord, installez la dépendance.
github.com/redis/rueidis
Ensuite, écrivez le code pour interroger les données dans Redis.
1package main
2
3import (
4 "context"
5 "log/slog"
6 "os"
7 "os/signal"
8 "time"
9
10 "github.com/redis/rueidis"
11)
12
13func main() {
14 ctx, cancel := signal.NotifyContext(context.Background(), os.Interrupt)
15 defer cancel()
16
17 client, err := rueidis.NewClient(rueidis.ClientOption{
18 InitAddress: []string{"localhost:6379"},
19 })
20 if err != nil {
21 panic(err)
22 }
23
24 ticker := time.NewTicker(1 * time.Second)
25 defer ticker.Stop()
26 done := ctx.Done()
27
28 for {
29 select {
30 case <-done:
31 slog.Info("shutting down")
32 return
33 case <-ticker.C:
34 const key = "key"
35 resp := client.DoCache(ctx, client.B().Get().Key(key).Cache(), 10*time.Second)
36 if resp.Error() != nil {
37 slog.Error("failed to get key", "error", resp.Error())
38 continue
39 }
40 i, err := resp.AsInt64()
41 if err != nil {
42 slog.Error("failed to convert response to int64", "error", err)
43 continue
44 }
45 switch resp.IsCacheHit() {
46 case true:
47 slog.Info("cache hit", "key", key)
48 case false:
49 slog.Info("missed key", "key", key)
50 }
51 slog.Info("got key", "value", i)
52 }
53 }
54}
Avec rueidis, il suffit d'utiliser DoCache pour utiliser le cache côté client. Cela ajoute les données au cache local, y compris la durée de conservation, et un appel ultérieur à DoCache récupérera les données du cache local. Il gère également correctement les messages d'invalidation.
Pourquoi pas redis-go ?
redis-go ne prend malheureusement pas en charge le cache côté client assisté par le serveur via une API officielle. De plus, lors de la création de PubSub, une nouvelle connexion est établie, et il n'y a pas d'API pour accéder directement à cette connexion, ce qui rend impossible de connaître l'ID du client. J'ai donc considéré que la configuration avec redis-go était impossible et l'ai ignorée.
C'est élégant
Grâce à la structure du cache côté client
- Si les données peuvent être préparées à l'avance, cette structure permettra de minimiser les requêtes et le trafic vers Redis tout en fournissant toujours les données les plus récentes.
- Cela permet de créer une sorte de structure CQRS pour améliorer considérablement les performances de lecture.

À quel point est-ce devenu plus élégant ?
Comme cette structure est actuellement utilisée en production, j'ai effectué une brève analyse de la latence pour deux API. Veuillez excuser le caractère très abstrait de cette explication.
- Première API
- Première consultation : moyenne de 14,63 ms
- Consultations ultérieures : moyenne de 2,82 ms
- Écart moyen : 10,98 ms
- Deuxième API
- Première consultation : moyenne de 14,05 ms
- Consultations ultérieures : moyenne de 1,60 ms
- Écart moyen : 11,57 ms
Il y a eu une amélioration supplémentaire de la latence allant jusqu'à 82 % !
Je m'attends à ce que les améliorations suivantes aient été réalisées :
- Suppression du processus de communication réseau entre le client et Redis et économie de trafic.
- Réduction du nombre de commandes de lecture que Redis doit exécuter.
- Cela a également pour effet d'améliorer les performances d'écriture.
- Minimisation du parsing du protocole Redis.
- Le parsing du protocole Redis n'est pas sans coût. Le réduire est une grande opportunité.
Cependant, tout est une question de compromis. Pour cela, nous avons sacrifié au moins deux choses :
- La nécessité d'implémenter, d'opérer et de maintenir la gestion des éléments du cache côté client.
- L'augmentation de l'utilisation du CPU et de la mémoire du client qui en résulte.
Conclusion
Personnellement, j'ai trouvé cette architecture très satisfaisante, avec une latence et un stress sur le serveur API très faibles. À l'avenir, si possible, j'aimerais continuer à configurer l'architecture de cette manière.