Présentation de Randflake ID : un générateur d'ID aléatoires distribué, uniforme, imprévisible et unique.
Considérons une situation où nous devons générer des nombres aléatoires uniques de 64 bits, et où des tiers externes ne devraient pas être en mesure de prédire le nombre suivant ou précédent.
Dans ce cas, nous pouvons générer une valeur aléatoire de 8 octets, vérifier si elle existe déjà dans la base de données, puis la stocker si elle est unique.
Cependant, cette méthode présente plusieurs inconvénients. Nous devons stocker chaque nombre généré dans une base de données pour garantir son unicité. L'exigence d'au moins un aller-retour vers la base de données crée des problèmes de latence, en particulier dans un environnement distribué où l'évolutivité est cruciale.
Pour résoudre ces problèmes, nous introduisons Randflake ID : un générateur d'ID aléatoires distribué, uniforme, imprévisible et unique.
Comment fonctionne l'ID Randflake ?
Randflake ID s'inspire de Snowflake ID, le mécanisme de génération d'ID k-triés largement utilisé et développé par X (anciennement Twitter).
Snowflake ID utilise l'horodatage actuel, un ID de nœud et un compteur local pour générer un identifiant.
Nous avons étendu cette approche pour la génération d'ID uniques aléatoires et avons ajouté un nouvel élément de clé secrète.
L'idée clé est d'ajouter une couche de chiffrement par bloc au générateur d'ID unique existant pour rendre infaisable la prédiction de la relation entre les nombres.
Un chiffrement par bloc est une fonction cryptographique fondamentale qui transforme un bloc de texte en clair de longueur fixe en un bloc de texte chiffré de même longueur. Cette transformation est régie par une clé cryptographique. La caractéristique distinctive d'un chiffrement par bloc est sa réversibilité : il doit s'agir d'une fonction biunivoque (bijective), garantissant que chaque entrée unique correspond à une sortie unique, et vice versa. Cette propriété est cruciale pour le déchiffrement, permettant de récupérer le texte en clair original à partir du texte chiffré lorsque la clé correcte est appliquée.
En employant un chiffrement par bloc comme fonction biunivoque, nous pouvons garantir que chaque entrée unique produit une sortie unique correspondante dans la plage définie.
La structure et les considérations de conception
En nous appuyant sur ces concepts fondamentaux, examinons comment Randflake ID met en œuvre ces idées dans la pratique.
La structure de Randflake ID comprend un horodatage Unix de 30 bits avec une précision à la seconde, un identifiant de nœud de 17 bits, un compteur local de 17 bits et un chiffrement par bloc de 64 bits basé sur l'algorithme sparx64.
Voici quelques décisions de conception :
Certaines instances de machines virtuelles dans Google Cloud Platform peuvent synchroniser l'horloge avec une précision de 0,2 ms, mais ce niveau de précision n'est pas disponible sur l'Internet public ou d'autres fournisseurs de cloud.
Nous avons choisi une précision à la seconde car nous ne pouvons synchroniser efficacement l'horloge entre les nœuds qu'avec une résolution de quelques millisecondes.
L'identifiant de nœud de 17 bits permet 131072 générateurs individuels au même moment, qui peuvent être attribués par processus, par cœur, par thread.
Dans les systèmes à haut débit, un compteur local de 17 bits peut être insuffisant. Pour égaler le débit, nous pouvons attribuer plusieurs générateurs, chacun avec un ID de nœud distinct, pour travailler dans un seul processus ou thread.
Nous avons adopté sparx64 comme chiffrement par bloc de 64 bits, un chiffrement par bloc moderne et léger basé sur ARX.
Les ID Randflake offrent une traçabilité interne, révélant leur ID de nœud d'origine et leur horodatage uniquement à ceux qui possèdent la clé secrète.
Le débit théorique maximal est de 17 179 869 184 ID/s, ce qui est suffisant pour la plupart des applications à l'échelle mondiale.
Pseudocode de génération d'ID Randflake
Pour illustrer davantage le processus de génération d'ID Randflake, le pseudocode Python suivant fournit une implémentation simplifiée :
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constantes
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Dimanche 27 octobre 2024 3:33:20 AM UTC
7
8# Allocation de bits
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bits pour l'horodatage (durée de vie de 34 ans)
10RANDFLAKE_NODE_BITS = 17 # 17 bits pour l'ID du nœud (max 131072 nœuds)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bits pour la séquence (max 131072 séquences)
12
13# Constantes dérivées
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Une implémentation de Randflake prête pour la production, intégrant un mécanisme de bail d'ID de nœud, est disponible sur GitHub.
Autres considérations
Dans cette section, nous examinerons quelques considérations supplémentaires pour l'implémentation de Randflake ID.
Coordination des ID de nœud
Nous suggérons une coordination des ID de nœud basée sur le bail.
Dans cette approche, un service de coordination central attribue un ID de nœud unique à chaque générateur.
Cet ID de nœud n'est pas réattribué pendant la période de bail afin de garantir l'unicité, réduisant ainsi le besoin de communications fréquentes avec le service de coordination.
Le générateur détenant le bail peut demander un renouvellement du bail auprès du service de coordination si la condition de renouvellement est remplie.
La condition de renouvellement fait référence à un ensemble de critères qui doivent être satisfaits pour que le bail soit renouvelé, tels que le générateur étant toujours actif et nécessitant l'ID de nœud.
Le preneur de bail est le détenteur actuel de la plage d'ID de nœud.
Le bail est considéré comme actif et non expiré s'il se trouve dans sa période de validité.
De cette manière, nous pouvons réduire les allers-retours à un par période de renouvellement de bail, minimisant la latence et améliorant l'efficacité dans les systèmes distribués.
Atténuation contre les horloges défectueuses
Le service de bail doit vérifier la cohérence de l'horodatage lors de l'attribution d'un bail. L'heure de début du bail attribué doit être supérieure ou égale à l'heure de début du dernier bail.
Le générateur doit rejeter la requête si l'horodatage actuel est inférieur à l'heure de début du bail ou supérieur à l'heure de fin du bail.
Cette procédure est importante pour protéger l'unicité des ID générés lorsque l'horloge recule. Par exemple, si une horloge recule, un nouveau bail pourrait être attribué avec une heure de début antérieure à un bail précédemment attribué, ce qui pourrait potentiellement entraîner la génération d'ID en double. En rejetant les requêtes avec des horodatages dans une période de bail existante, nous évitons ce scénario et maintenons l'unicité des ID.
Uniformité de la distribution des ID
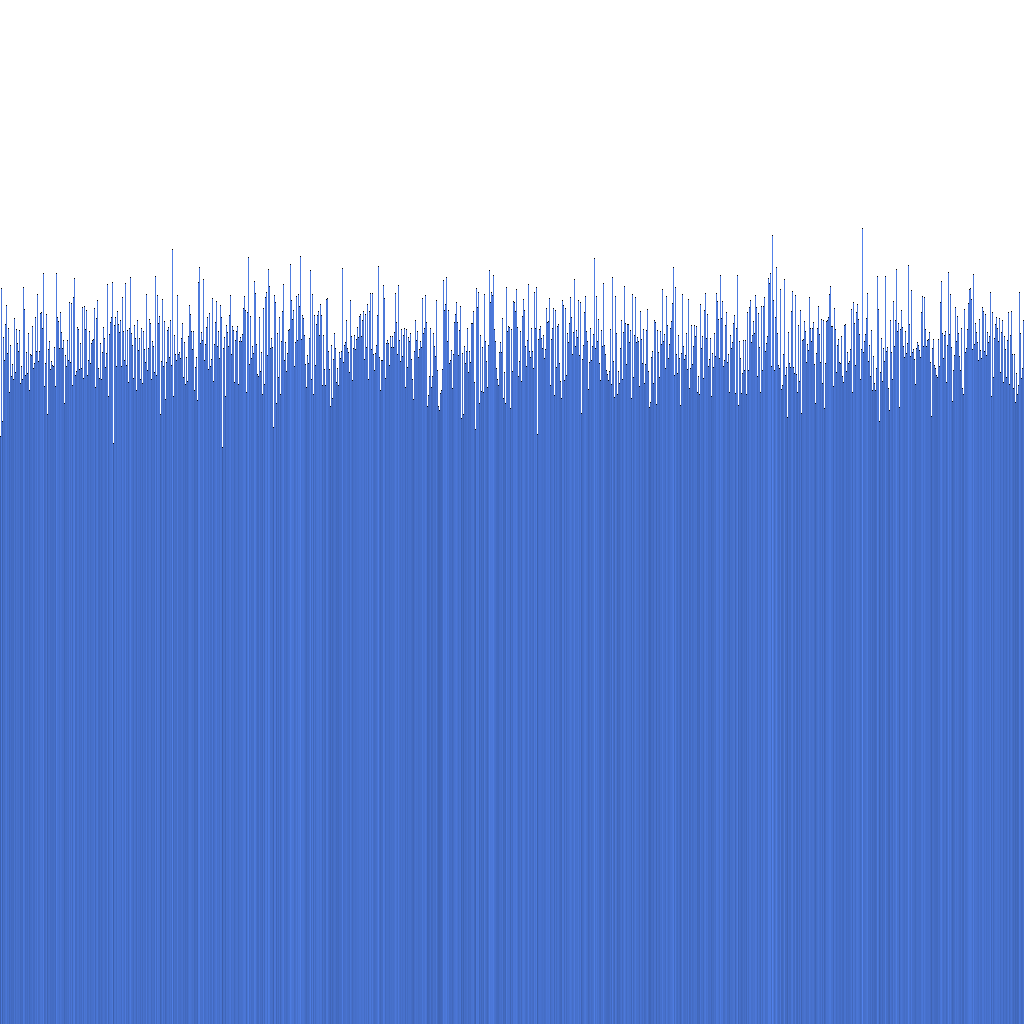
D'après l'histogramme ci-dessus, nous pouvons constater que la distribution des ID Randflake générés est très uniforme. Cela suggère que la distribution des ID peut être utilisée directement comme clé de sharding.
Conclusion
Dans cet article, nous avons introduit Randflake, un nouvel algorithme de génération d'ID qui combine les avantages de Snowflake et de Sparx64.
Nous espérons que cet article vous a fourni une compréhension complète de Randflake et de son implémentation.
Vous pouvez trouver le code source complet de Randflake sur GitHub.
Si vous avez des questions ou des suggestions, n'hésitez pas à nous contacter. Nous recherchons également des contributeurs pour aider à améliorer Randflake et à l'implémenter dans d'autres langages de programmation.
Nous prévoyons de publier un service de coordination prêt pour la production pour Randflake et Snowflake, qui sera open-source sur GitHub. Restez à l'écoute pour les mises à jour !