Memperkenalkan Randflake ID: generator ID acak yang terdistribusi, seragam, tidak dapat diprediksi, dan unik.
Pertimbangkan situasi di mana kita perlu membuat bilangan acak 64-bit yang unik, dan pihak eksternal tidak dapat memprediksi bilangan berikutnya atau sebelumnya.
Di sini, kita dapat menghasilkan nilai acak 8-byte, memeriksa apakah nilai tersebut sudah ada di database, lalu menyimpannya jika unik.
Namun, metode ini memiliki beberapa kelemahan. Kita harus menyimpan setiap bilangan yang dihasilkan dalam database untuk memastikan keunikan. Persyaratan setidaknya satu perjalanan pulang-pergi ke database menciptakan masalah latensi, terutama di lingkungan terdistribusi di mana skalabilitas sangat penting.
Untuk mengatasi masalah ini, kami memperkenalkan Randflake ID: generator ID acak terdistribusi, seragam, tidak dapat diprediksi, dan unik.
Bagaimana Randflake ID Bekerja?
Randflake ID terinspirasi oleh Snowflake ID, mekanisme pembuatan ID k-sorted yang banyak digunakan yang dikembangkan oleh X (sebelumnya twitter).
Snowflake ID menggunakan stempel waktu saat ini, ID node, dan penghitung lokal untuk menghasilkan pengidentifikasi.
Kami mengembangkan pendekatan ini lebih lanjut untuk pembuatan ID unik acak dan menambahkan elemen kunci rahasia baru.
Gagasan utamanya adalah menambahkan lapisan block cipher ke generator ID unik yang ada untuk mencapai ketidakmungkinan dalam memprediksi hubungan antara bilangan.
Block cipher adalah fungsi kriptografi fundamental yang mengubah blok plaintext dengan panjang tetap menjadi blok ciphertext dengan panjang yang sama. Transformasi ini diatur oleh kunci kriptografi. Karakteristik pembeda block cipher adalah reversibilitasnya: ia harus merupakan fungsi satu-ke-satu (bijektif), memastikan bahwa setiap input unik sesuai dengan output unik, dan sebaliknya. Properti ini krusial untuk dekripsi, memungkinkan plaintext asli dipulihkan dari ciphertext ketika kunci yang benar diterapkan.
Dengan menggunakan block cipher sebagai fungsi satu-ke-satu, kita dapat menjamin bahwa setiap input unik menghasilkan output unik yang sesuai dalam rentang yang ditentukan.
Struktur dan pertimbangan desain
Berdasarkan konsep-konsep fundamental ini, mari kita periksa bagaimana Randflake ID mengimplementasikan ide-ide ini dalam praktik.
Struktur Randflake ID mencakup stempel waktu unix 30-bit dengan presisi detik, pengidentifikasi node 17-bit, penghitung lokal 17-bit, dan block cipher 64-bit berdasarkan algoritma sparx64.
Berikut adalah beberapa keputusan desain:
Beberapa instans VM di Google Cloud Platform dapat menyinkronkan jam dalam presisi 0,2ms, tetapi tingkat akurasi tersebut tidak tersedia di internet publik atau penyedia cloud lainnya.
Kami memilih presisi detik karena kami dapat secara efektif menyinkronkan jam antar node hanya dalam resolusi beberapa milidetik.
Pengidentifikasi node 17-bit memungkinkan 131072 generator individual pada saat yang sama, yang dapat ditetapkan per-proses, per-core, per-thread.
Dalam sistem throughput tinggi, penghitung lokal 17-bit mungkin tidak mencukupi. Untuk mencocokkan throughput, kita dapat menetapkan beberapa generator, masing-masing dengan ID node yang berbeda, untuk bekerja dalam satu proses atau thread.
Kami mengadopsi sparx64 sebagai block cipher 64-bit, sebuah block cipher ARX-based ringan modern.
Randflake ID menawarkan ketertelusuran internal, mengungkapkan ID node asal dan stempel waktunya hanya kepada mereka yang memiliki kunci rahasia.
Throughput maksimum teoritis adalah 17.179.869.184 ID/dtk, yang cukup untuk sebagian besar aplikasi berskala global.
Pseudocode pembuatan Randflake ID
Untuk mengilustrasikan lebih lanjut proses pembuatan Randflake ID, pseudocode Python berikut menyediakan implementasi yang disederhanakan:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Minggu, 27 Oktober 2024 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bit untuk stempel waktu (masa pakai 34 tahun)
10RANDFLAKE_NODE_BITS = 17 # 17 bit untuk ID node (maks 131072 node)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bit untuk urutan (maks 131072 urutan)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Implementasi Randflake yang siap produksi, menampilkan mekanisme sewa ID node, tersedia di GitHub.
Pertimbangan lain
Pada bagian ini, kita akan membahas beberapa pertimbangan tambahan untuk mengimplementasikan Randflake ID.
Koordinasi ID Node
Kami menyarankan koordinasi ID node berbasis sewa.
Dalam pendekatan ini, layanan koordinasi pusat menetapkan ID node unik untuk setiap generator.
ID node ini tidak ditetapkan ulang selama periode sewa untuk memastikan keunikan, mengurangi kebutuhan komunikasi yang sering dengan layanan koordinasi.
Generator yang memegang sewa dapat meminta perpanjangan sewa dari layanan koordinasi jika kondisi perpanjangan terpenuhi.
Kondisi perpanjangan mengacu pada serangkaian kriteria yang harus dipenuhi agar sewa dapat diperbarui, seperti generator masih aktif dan membutuhkan ID node.
Pemegang sewa adalah pemegang rentang ID node saat ini.
Sewa dianggap aktif dan tidak kedaluwarsa jika berada dalam periode waktu validnya.
Dengan cara ini, kita dapat mengurangi perjalanan pulang-pergi menjadi satu per periode perpanjangan sewa, meminimalkan latensi dan meningkatkan efisiensi dalam sistem terdistribusi.
Mitigasi terhadap jam yang salah
Layanan sewa harus memeriksa konsistensi stempel waktu saat mengalokasikan sewa. Waktu mulai sewa yang ditetapkan harus lebih besar dari atau sama dengan waktu mulai sewa terakhir.
Generator harus menolak permintaan jika stempel waktu saat ini kurang dari waktu mulai sewa atau lebih besar dari waktu berakhir sewa.
Prosedur ini penting untuk melindungi keunikan ID yang dihasilkan ketika jam melompat mundur. Misalnya, jika jam melompat mundur, sewa baru dapat ditetapkan dengan waktu mulai lebih awal dari sewa yang ditetapkan sebelumnya, yang berpotensi menyebabkan ID duplikat dihasilkan. Dengan menolak permintaan dengan stempel waktu dalam periode sewa yang ada, kami mencegah skenario ini dan mempertahankan keunikan ID.
Keseragaman distribusi ID
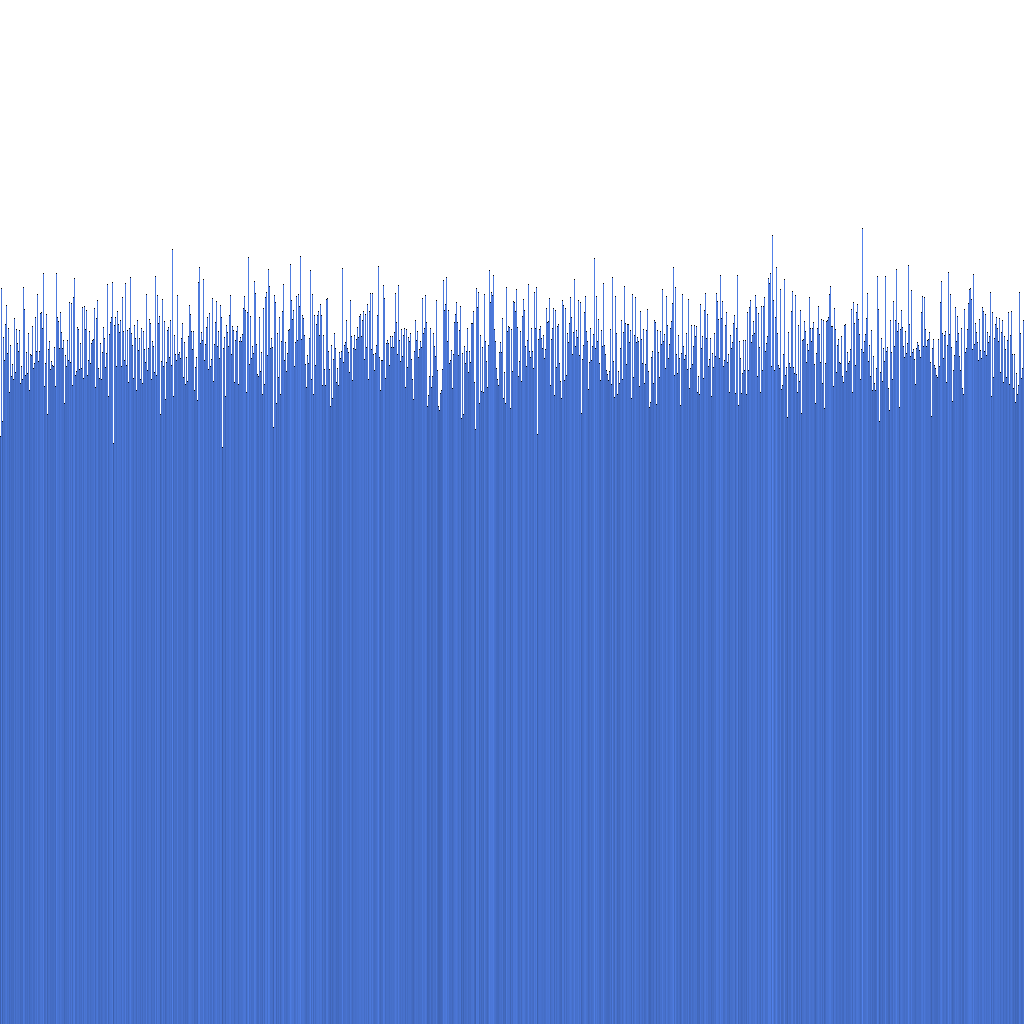
Berdasarkan histogram di atas, kita dapat melihat bahwa distribusi Randflake ID yang dihasilkan sangat seragam. Ini menunjukkan bahwa distribusi ID dapat digunakan secara langsung sebagai kunci sharding.
Kesimpulan
Dalam artikel ini, kami memperkenalkan Randflake, algoritma pembuatan ID baru yang menggabungkan keunggulan Snowflake dan Sparx64.
Kami berharap artikel ini telah memberi Anda pemahaman komprehensif tentang Randflake dan implementasinya.
Anda dapat menemukan kode sumber lengkap untuk Randflake di GitHub.
Jika Anda memiliki pertanyaan atau saran, jangan ragu untuk menghubungi kami. Kami juga mencari kontributor untuk membantu meningkatkan Randflake dan mengimplementasikannya dalam bahasa pemrograman lain.
Kami berencana untuk merilis layanan koordinasi siap produksi untuk Randflake dan Snowflake, yang akan di-open-source di GitHub. Nantikan pembaruan!