Migliorare la reattività con la Client-Side Caching di Redis
What is Redis?
Non credo ci sia qualcuno che non conosca Redis. Tuttavia, per riassumere brevemente alcune delle sue caratteristiche, possiamo elencare quanto segue:
- Le operazioni sono eseguite in un singolo thread, conferendo a tutte le operazioni atomicità.
- I dati sono memorizzati ed elaborati In-Memory, rendendo tutte le operazioni veloci.
- Redis può salvare il WAL a seconda delle opzioni, consentendo un rapido backup e ripristino dello stato più recente.
- Supporta vari tipi come Set, Hash, Bit, List, garantendo un'elevata produttività.
- Ha una grande community, permettendo la condivisione di diverse esperienze, problemi e soluzioni.
- È stato sviluppato e gestito per lungo tempo, offrendo un'affidabile stabilità.
E quindi, al punto
Immaginate?
Cosa succederebbe se la cache del vostro servizio soddisfacesse le seguenti due condizioni?
- Quando i dati consultati frequentemente devono essere forniti all'utente nello stato più recente, ma gli aggiornamenti sono irregolari e la cache deve essere aggiornata frequentemente.
- Quando gli aggiornamenti non sono necessari, ma si accede frequentemente agli stessi dati della cache per la consultazione.
Il primo caso potrebbe riguardare la classifica di popolarità in tempo reale di un centro commerciale. Se la classifica di popolarità in tempo reale di un centro commerciale fosse memorizzata come un sorted set, sarebbe inefficiente per Redis leggerla ogni volta che un utente accede alla pagina principale. Nel secondo caso, per i dati sui tassi di cambio, anche se i dati vengono pubblicati approssimativamente ogni 10 minuti, le consultazioni effettive avvengono molto frequentemente. Inoltre, la cache viene consultata molto spesso per i tassi di cambio Won-Dollaro, Won-Yen e Won-Yuan. In questi casi, sarebbe più efficiente che il server API avesse una cache separata localmente e, quando i dati cambiano, consultasse nuovamente Redis per aggiornarli.
Come si può implementare un tale comportamento in una struttura Database - Redis - Server API?
Non è possibile con Redis PubSub?
Quando si utilizza la cache, sottoscriviamo un canale che può ricevere notifiche di aggiornamento!
- Quindi è necessario creare una logica per inviare messaggi al momento dell'aggiornamento.
- L'aggiunta di operazioni dovute a PubSub influisce sulle prestazioni.
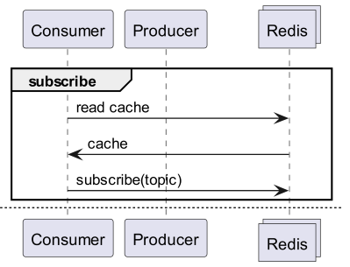
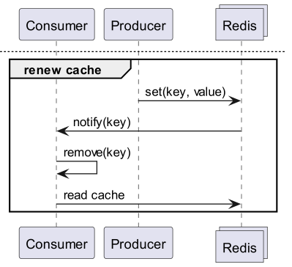
E se Redis rilevasse i cambiamenti?
E se ricevessimo notifiche di comando per una data chiave usando Keyspace Notification?
- C'è l'inconveniente di dover pre-memorizzare e condividere le chiavi e i comandi utilizzati per l'aggiornamento.
- Ad esempio, per alcune chiavi un semplice Set è il comando di aggiornamento, mentre per altre chiavi LPush, o RPush, o SAdd e SRem sono i comandi di aggiornamento, rendendo il tutto più complesso.
- Ciò aumenta notevolmente la possibilità di errori di comunicazione e di errori umani nella codifica durante il processo di sviluppo.
E se ricevessimo notifiche per unità di comando usando Keyevent Notification?
- È necessaria la sottoscrizione a tutti i comandi utilizzati per l'aggiornamento. È necessaria una filtrazione appropriata per le chiavi in arrivo.
- Ad esempio, è probabile che un client non abbia una cache locale per alcune delle chiavi che arrivano tramite Del.
- Ciò può portare a uno spreco inutile di risorse.
Quindi ciò che serve è l'Invalidation Message!
Che cos'è l'Invalidation Message?
Gli Invalidation Messages sono un concetto fornito come parte di Server Assisted Client-Side Cache, aggiunto a partire da Redis 6.0. Un Invalidation Message viene trasmesso con il seguente flusso:
- Si assume che ClientB abbia già letto una chiave.
- ClientA imposta nuovamente quella chiave.
- Redis rileva il cambiamento e invia un Invalidation Message a ClientB, notificandolo di cancellare la cache.
- ClientB riceve il messaggio e intraprende l'azione appropriata.
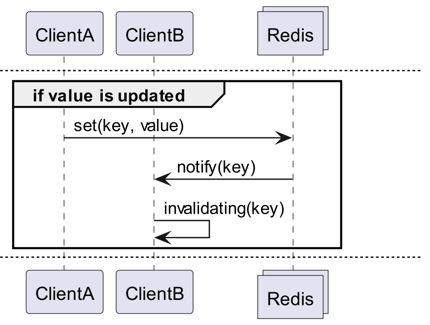
Come si usa
Struttura operativa di base
Un client connesso a Redis esegue CLIENT TRACKING ON REDIRECT <client-id> per ricevere i messaggi di invalidazione. Il client che deve ricevere i messaggi si sottoscrive a SUBSCRIBE __redis__:invalidate per ricevere i messaggi di invalidazione.
default tracking
1# client 1
2> SET a 100
1# client 3
2> CLIENT ID
312
4> SUBSCRIBE __redis__:invalidate
51) "subscribe"
62) "__redis__:invalidate"
73) (integer) 1
1# client 2
2> CLIENT TRACKING ON REDIRECT 12
3> GET a # tracking
1# client 1
2> SET a 200
1# client 3
21) "message"
32) "__redis__:invalidate"
43) 1) "a"
broadcasting tracking
1# client 3
2> CLIENT ID
312
4> SUBSCRIBE __redis__:invalidate
51) "subscribe"
62) "__redis__:invalidate"
73) (integer) 1
1# client 2
2CLIENT TRACKING ON BCAST PREFIX cache: REDIRECT 12
1# client 1
2> SET cache:name "Alice"
3> SET cache:age 26
1# client 3
21) "message"
32) "__redis__:invalidate"
43) 1) "cache:name"
51) "message"
62) "__redis__:invalidate"
73) 1) "cache:age"
Implementazione! Implementazione! Implementazione!
Redigo + Ristretto
Spiegare solo così rende ambiguo come usarlo nel codice. Quindi, configuriamolo prima con redigo e ristretto.
Installare prima le due dipendenze.
github.com/gomodule/redigogithub.com/dgraph-io/ristretto
1package main
2
3import (
4 "context"
5 "fmt"
6 "log/slog"
7 "time"
8
9 "github.com/dgraph-io/ristretto"
10 "github.com/gomodule/redigo/redis"
11)
12
13type RedisClient struct {
14 conn redis.Conn
15 cache *ristretto.Cache[string, any]
16 addr string
17}
18
19func NewRedisClient(addr string) (*RedisClient, error) {
20 cache, err := ristretto.NewCache(&ristretto.Config[string, any]{
21 NumCounters: 1e7, // numero di chiavi di cui tracciare la frequenza (10M).
22 MaxCost: 1 << 30, // costo massimo della cache (1GB).
23 BufferItems: 64, // numero di chiavi per buffer Get.
24 })
25 if err != nil {
26 return nil, fmt.Errorf("failed to generate cache: %w", err)
27 }
28
29 conn, err := redis.Dial("tcp", addr)
30 if err != nil {
31 return nil, fmt.Errorf("failed to connect to redis: %w", err)
32 }
33
34 return &RedisClient{
35 conn: conn,
36 cache: cache,
37 addr: addr,
38 }, nil
39}
40
41func (r *RedisClient) Close() error {
42 err := r.conn.Close()
43 if err != nil {
44 return fmt.Errorf("failed to close redis connection: %w", err)
45 }
46
47 return nil
48}
Per prima cosa, creiamo un semplice RedisClient che includa ristretto e redigo.
1func (r *RedisClient) Tracking(ctx context.Context) error {
2 psc, err := redis.Dial("tcp", r.addr)
3 if err != nil {
4 return fmt.Errorf("failed to connect to redis: %w", err)
5 }
6
7 clientId, err := redis.Int64(psc.Do("CLIENT", "ID"))
8 if err != nil {
9 return fmt.Errorf("failed to get client id: %w", err)
10 }
11 slog.Info("client id", "id", clientId)
12
13 subscriptionResult, err := redis.String(r.conn.Do("CLIENT", "TRACKING", "ON", "REDIRECT", clientId))
14 if err != nil {
15 return fmt.Errorf("failed to enable tracking: %w", err)
16 }
17 slog.Info("subscription result", "result", subscriptionResult)
18
19 if err := psc.Send("SUBSCRIBE", "__redis__:invalidate"); err != nil {
20 return fmt.Errorf("failed to subscribe: %w", err)
21 }
22 psc.Flush()
23
24 for {
25 msg, err := psc.Receive()
26 if err != nil {
27 return fmt.Errorf("failed to receive message: %w", err)
28 }
29
30 switch msg := msg.(type) {
31 case redis.Message:
32 slog.Info("received message", "channel", msg.Channel, "data", msg.Data)
33 key := string(msg.Data)
34 r.cache.Del(key)
35 case redis.Subscription:
36 slog.Info("subscription", "kind", msg.Kind, "channel", msg.Channel, "count", msg.Count)
37 case error:
38 return fmt.Errorf("error: %w", msg)
39 case []interface{}:
40 if len(msg) != 3 || string(msg[0].([]byte)) != "message" || string(msg[1].([]byte)) != "__redis__:invalidate" {
41 slog.Warn("unexpected message", "message", msg)
42 continue
43 }
44
45 contents := msg[2].([]interface{})
46 keys := make([]string, len(contents))
47 for i, key := range contents {
48 keys[i] = string(key.([]byte))
49 r.cache.Del(keys[i])
50 }
51 slog.Info("received invalidation message", "keys", keys)
52 default:
53 slog.Warn("unexpected message", "type", fmt.Sprintf("%T", msg))
54 }
55 }
56}
Il codice è un po' complesso.
- Per il Tracking, viene stabilita una connessione aggiuntiva. Questa misura è stata adottata per evitare che PubSub interferisse con altre operazioni.
- Viene interrogato l'ID della connessione aggiunta, e il Tracking viene reindirizzato a quella connessione dalla connessione che interrogherà i dati.
- Quindi ci si sottoscrive all'invalidation message.
- Il codice per gestire la sottoscrizione è un po' complesso. Poiché redigo non supporta il parsing dei messaggi di invalidazione, è necessario ricevere la risposta prima del parsing per gestirli.
1func (r *RedisClient) Get(key string) (any, error) {
2 val, found := r.cache.Get(key)
3 if found {
4 switch v := val.(type) {
5 case int64:
6 slog.Info("cache hit", "key", key)
7 return v, nil
8 default:
9 slog.Warn("unexpected type", "type", fmt.Sprintf("%T", v))
10 }
11 }
12 slog.Info("cache miss", "key", key)
13
14 val, err := redis.Int64(r.conn.Do("GET", key))
15 if err != nil {
16 return nil, fmt.Errorf("failed to get key: %w", err)
17 }
18
19 r.cache.SetWithTTL(key, val, 1, 10*time.Second)
20 return val, nil
21}
Il messaggio Get per prima cosa interroga Ristretto e, se non lo trova, lo recupera da Redis.
1package main
2
3import (
4 "context"
5 "log/slog"
6 "os"
7 "os/signal"
8 "time"
9)
10
11func main() {
12 ctx, cancel := signal.NotifyContext(context.Background(), os.Interrupt)
13 defer cancel()
14
15 client, err := NewRedisClient("localhost:6379")
16 if err != nil {
17 panic(err)
18 }
19 defer client.Close()
20
21 go func() {
22 if err := client.Tracking(ctx); err != nil {
23 slog.Error("failed to track invalidation message", "error", err)
24 }
25 }()
26
27 ticker := time.NewTicker(1 * time.Second)
28 defer ticker.Stop()
29 done := ctx.Done()
30
31 for {
32 select {
33 case <-done:
34 slog.Info("shutting down")
35 return
36 case <-ticker.C:
37 v, err := client.Get("key")
38 if err != nil {
39 slog.Error("failed to get key", "error", err)
40 return
41 }
42 slog.Info("got key", "value", v)
43 }
44 }
45}
Il codice per il test è quello sopra. Se lo provate, potrete verificare che i valori vengono aggiornati ogni volta che i dati in Redis vengono modificati.
Tuttavia, ciò è troppo complesso. Soprattutto, per scalare a un cluster, è inevitabile attivare il Tracking su tutti i master o le repliche.
Rueidis
Per chi usa Go, abbiamo rueidis, il più moderno e avanzato. Scriveremo codice che utilizza la server assisted client side cache in un ambiente cluster Redis usando rueidis.
Per prima cosa, installate la dipendenza.
github.com/redis/rueidis
Quindi, scrivete il codice per interrogare i dati in Redis.
1package main
2
3import (
4 "context"
5 "log/slog"
6 "os"
7 "os/signal"
8 "time"
9
10 "github.com/redis/rueidis"
11)
12
13func main() {
14 ctx, cancel := signal.NotifyContext(context.Background(), os.Interrupt)
15 defer cancel()
16
17 client, err := rueidis.NewClient(rueidis.ClientOption{
18 InitAddress: []string{"localhost:6379"},
19 })
20 if err != nil {
21 panic(err)
22 }
23
24 ticker := time.NewTicker(1 * time.Second)
25 defer ticker.Stop()
26 done := ctx.Done()
27
28 for {
29 select {
30 case <-done:
31 slog.Info("shutting down")
32 return
33 case <-ticker.C:
34 const key = "key"
35 resp := client.DoCache(ctx, client.B().Get().Key(key).Cache(), 10*time.Second)
36 if resp.Error() != nil {
37 slog.Error("failed to get key", "error", resp.Error())
38 continue
39 }
40 i, err := resp.AsInt64()
41 if err != nil {
42 slog.Error("failed to convert response to int64", "error", err)
43 continue
44 }
45 switch resp.IsCacheHit() {
46 case true:
47 slog.Info("cache hit", "key", key)
48 case false:
49 slog.Info("missed key", "key", key)
50 }
51 slog.Info("got key", "value", i)
52 }
53 }
54}
Con rueidis, per usare la client side cache, basta chiamare DoCache. Questo aggiunge i dati alla cache locale (con un tempo di mantenimento specificato) e, se si chiama DoCache di nuovo, recupera i dati dalla cache locale. Naturalmente, gestisce correttamente anche i messaggi di invalidazione.
Perché non redis-go?
redis-go purtroppo non supporta ufficialmente la server assisted client side cache tramite API. Inoltre, quando si crea un PubSub, non esiste un'API per accedere direttamente alla nuova connessione creata, quindi non è possibile conoscere l'ID del client. Per questi motivi, ho deciso di scartare redis-go, ritenendo che la sua configurazione fosse impossibile.
Che fascino
Attraverso la struttura della client side cache
- Se i dati possono essere preparati in anticipo, questa struttura consentirà di fornire sempre i dati più recenti, minimizzando le query e il traffico verso Redis.
- Ciò consentirà di creare una sorta di struttura CQRS, migliorando drasticamente le prestazioni di lettura.

Quanto è diventato più affascinante?
In effetti, poiché una tale struttura è attualmente in uso, ho cercato semplici latenze per le due API. Vi prego di comprendere che posso solo scriverlo in modo molto astratto.
- Prima API
- Prima query: media 14.63ms
- Query successive: media 2.82ms
- Differenza media: 10.98ms
- Seconda API
- Prima query: media 14.05ms
- Query successive: media 1.60ms
- Differenza media: 11.57ms
C'è stato un miglioramento della latenza aggiuntiva fino all'82%!
Mi aspetto che ci siano stati i seguenti miglioramenti:
- Eliminazione della comunicazione di rete tra client e Redis e risparmio di traffico.
- Riduzione del numero di comandi di lettura che Redis deve eseguire.
- Ciò ha anche l'effetto di aumentare le prestazioni di scrittura.
- Minimizzazione del parsing del protocollo Redis.
- Il parsing del protocollo Redis non è privo di costi. Ridurlo è una grande opportunità.
Tuttavia, tutto è un compromesso. Per questo, abbiamo sacrificato almeno i seguenti due aspetti:
- Necessità di implementare, operare e mantenere gli elementi di gestione della cache lato client.
- Aumento dell'utilizzo della CPU e della memoria del client a causa di ciò.
Conclusione
Personalmente, sono rimasto soddisfatto di questo componente architetturale, e la latenza e lo stress sul server API erano molto ridotti. Spero di poter continuare a configurare l'architettura in questo modo, se possibile.