Presentazione di Randflake ID: un generatore di ID casuali distribuito, uniforme, imprevedibile e unico.
Si consideri una situazione in cui è necessario generare numeri casuali unici a 64 bit e le parti esterne non dovrebbero essere in grado di prevedere il numero successivo o precedente.
Qui, possiamo generare un valore casuale di 8 byte, verificare se esiste già nel database e quindi memorizzarlo se è unico.
Tuttavia, questo metodo presenta diversi inconvenienti. Dobbiamo memorizzare ogni numero generato in un database per garantirne l'unicità. L'esigenza di almeno un round trip al database crea problemi di latenza, in particolare in un ambiente distribuito dove la scalabilità è cruciale.
Per risolvere questi problemi, stiamo introducendo Randflake ID: un generatore di ID casuali distribuito, uniforme, imprevedibile e unico.
Come funziona Randflake ID?
Randflake ID è ispirato a Snowflake ID, il meccanismo di generazione di ID k-ordinati ampiamente utilizzato e sviluppato da X (ex Twitter).
Snowflake ID utilizza il timestamp corrente, un ID di nodo e un contatore locale per generare un identificatore.
Abbiamo espanso ulteriormente questo approccio per la generazione di ID unici casuali e abbiamo aggiunto un nuovo elemento di chiave segreta.
L'idea chiave è aggiungere un livello di cifratura a blocchi al generatore di ID unico esistente per rendere infattibile la previsione della relazione tra i numeri.
Un cifrario a blocchi è una funzione crittografica fondamentale che trasforma un blocco di testo in chiaro a lunghezza fissa in un blocco di testo cifrato della stessa lunghezza. Questa trasformazione è governata da una chiave crittografica. La caratteristica distintiva di un cifrario a blocchi è la sua reversibilità: deve essere una funzione biunivoca (biettiva), garantendo che ogni input unico corrisponda a un output unico, e viceversa. Questa proprietà è cruciale per la decrittografia, consentendo di recuperare il testo in chiaro originale dal testo cifrato quando viene applicata la chiave corretta.
Impiegando un cifrario a blocchi come funzione biunivoca, possiamo garantire che ogni input unico produca un output unico corrispondente all'interno dell'intervallo definito.
La struttura e le considerazioni di progettazione
Basandoci su questi concetti fondamentali, esaminiamo come Randflake ID implementa queste idee nella pratica.
La struttura di Randflake ID include un timestamp Unix a 30 bit con precisione al secondo, un identificatore di nodo a 17 bit, un contatore locale a 17 bit e un cifrario a blocchi a 64 bit basato sull'algoritmo sparx64.
Ecco alcune decisioni di progettazione:
Alcune istanze VM in Google Cloud Platform possono sincronizzare l'orologio con una precisione di 0,2 ms, ma tale livello di accuratezza non è disponibile su Internet pubblico o altri provider di cloud.
Abbiamo selezionato una precisione al secondo perché possiamo sincronizzare efficacemente l'orologio tra i nodi solo con una risoluzione di pochi millisecondi.
L'identificatore di nodo a 17 bit consente 131072 generatori individuali nello stesso momento, che possono essere assegnati per-processo, per-core, per-thread.
Nei sistemi ad alta produttività, il contatore locale a 17 bit potrebbe essere insufficiente. Per eguagliare la produttività, possiamo assegnare più generatori, ognuno con un ID di nodo distinto, per lavorare in un singolo processo o thread.
Abbiamo adottato sparx64 come cifrario a blocchi a 64 bit, un moderno cifrario a blocchi leggero basato su ARX.
Gli ID Randflake offrono tracciabilità interna, rivelando il loro ID di nodo di origine e il timestamp solo a coloro che possiedono la chiave segreta.
La produttività massima teorica è di 17.179.869.184 ID/s, sufficiente per la maggior parte delle applicazioni su scala globale.
Pseudocodice per la generazione di Randflake ID
Per illustrare ulteriormente il processo di generazione di Randflake ID, il seguente pseudocodice Python fornisce un'implementazione semplificata:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Sunday, October 27, 2024 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bit per il timestamp (durata di 34 anni)
10RANDFLAKE_NODE_BITS = 17 # 17 bit per l'ID del nodo (max 131072 nodi)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bit per la sequenza (max 131072 sequenze)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Un'implementazione di Randflake pronta per la produzione, dotata di un meccanismo di lease per l'ID del nodo, è disponibile su GitHub.
Altre considerazioni
In questa sezione, discuteremo alcune considerazioni aggiuntive per l'implementazione di Randflake ID.
Coordinamento dell'ID del nodo
Suggeriamo un coordinamento dell'ID del nodo basato su lease.
In questo approccio, un servizio di coordinamento centrale assegna un ID di nodo unico a ciascun generatore.
Questo ID di nodo non viene riassegnato durante il periodo di lease per garantire l'unicità, riducendo la necessità di comunicazioni frequenti con il servizio di coordinamento.
Il generatore che detiene il lease può richiedere un rinnovo del lease al servizio di coordinamento se la condizione di rinnovo è soddisfatta.
La condizione di rinnovo si riferisce a un insieme di criteri che devono essere soddisfatti affinché il lease venga rinnovato, come il generatore che è ancora attivo e che richiede l'ID del nodo.
Il leaseholder è l'attuale detentore dell'intervallo di ID del nodo.
Il lease è considerato attivo e non scaduto se rientra nel suo periodo di validità.
In questo modo, possiamo ridurre i round trip a uno per periodo di rinnovo del lease, minimizzando la latenza e migliorando l'efficienza nei sistemi distribuiti.
Mitigazione contro l'orologio difettoso
Il servizio di lease deve verificare la coerenza del timestamp durante l'allocazione di un lease. L'ora di inizio del lease assegnato deve essere maggiore o uguale all'ora di inizio dell'ultimo lease.
Il generatore dovrebbe rifiutare la richiesta se il timestamp corrente è inferiore all'ora di inizio del lease o maggiore dell'ora di fine del lease.
Questa procedura è importante per proteggere l'unicità degli ID generati quando l'orologio torna indietro. Ad esempio, se un orologio torna indietro, un nuovo lease potrebbe essere assegnato con un'ora di inizio precedente a un lease assegnato in precedenza, portando potenzialmente alla generazione di ID duplicati. Rifiutando le richieste con timestamp all'interno di un periodo di lease esistente, preveniamo questo scenario e manteniamo l'unicità degli ID.
Uniformità della distribuzione degli ID
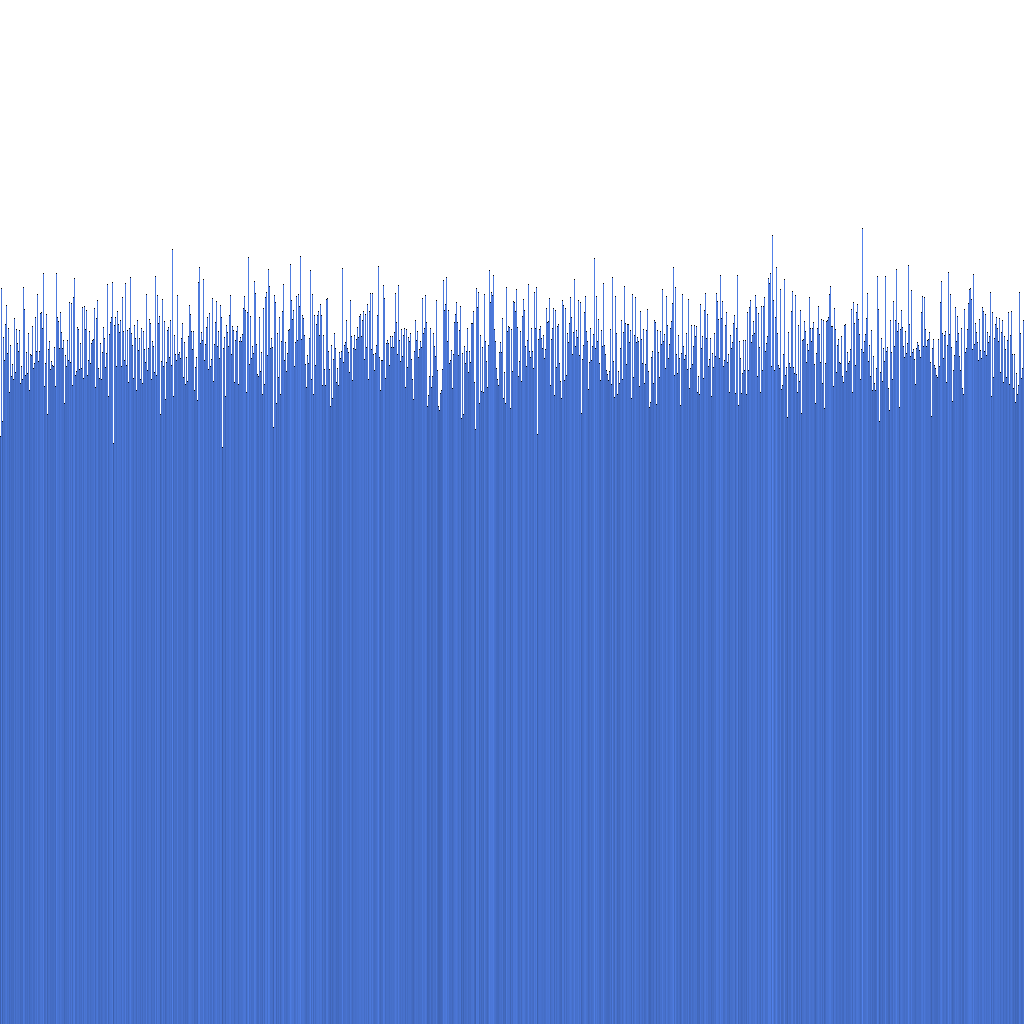
Basandoci sull'istogramma sopra, possiamo notare che la distribuzione degli ID Randflake generati è molto uniforme. Ciò suggerisce che la distribuzione degli ID può essere utilizzata direttamente come chiave di sharding.
Conclusione
In questo articolo, abbiamo introdotto Randflake, un nuovo algoritmo di generazione di ID che combina i vantaggi di Snowflake e Sparx64.
Ci auguriamo che questo articolo vi abbia fornito una comprensione completa di Randflake e della sua implementazione.
È possibile trovare il codice sorgente completo di Randflake su GitHub.
Se avete domande o suggerimenti, non esitate a contattarci. Cerchiamo anche contributori per aiutare a migliorare Randflake e implementarlo in altri linguaggi di programmazione.
Stiamo pianificando di rilasciare un servizio di coordinamento pronto per la produzione per Randflake e Snowflake, che sarà open-source su GitHub. Restate sintonizzati per gli aggiornamenti!