Randflake IDのご紹介:分散型で、均一性があり、予測不可能で、固有なランダムIDジェネレーターです。
一意な64ビットの乱数を生成する必要があり、外部の第三者が次の乱数または以前の乱数を予測できない状況を想定してください。
ここでは、8バイトのランダム値を生成し、それがすでにデータベースに存在するかどうかを確認し、一意であればそれを保存することができます。
しかしながら、この方法にはいくつかの欠点があります。一意性を保証するために、生成されたすべての乱数をデータベースに保存しなければなりません。データベースへの少なくとも1回のラウンドトリップが必要となるため、特にスケーラビリティが重要となる分散環境においては、レイテンシの問題が発生します。
これらの問題を解決するために、我々はRandflake IDを導入します。これは、分散型で、均一で、予測不可能で、一意なランダムIDジェネレーターです。
Randflake IDの仕組み
Randflake IDは、X(旧Twitter)が開発した広く使用されているkソートID生成メカニズムであるSnowflake IDに触発されています。
Snowflake IDは、現在のタイムスタンプ、ノードID、およびローカルカウンターを使用して識別子を生成します。
我々はこのアプローチをランダムな一意ID生成のためにさらに拡張し、新しい秘密鍵要素を追加しました。
主要なアイデアは、既存の一意IDジェネレーターにブロック暗号層を追加することで、数値間の関係を予測することの実現不可能性を達成することです。
ブロック暗号は、固定長の平文ブロックを同じ長さの暗号文ブロックに変換する基本的な暗号関数です。この変換は暗号鍵によって管理されます。ブロック暗号の際立った特徴はその可逆性です。つまり、各一意の入力が各一意の出力に対応し、その逆もまた成り立つことを保証する1対1(全単射)関数でなければなりません。この特性は復号化にとって重要であり、正しい鍵が適用された場合に暗号文から元の平文を復元することを可能にします。
ブロック暗号を1対1関数として利用することにより、各一意の入力が定義された範囲内で対応する一意の出力を生成することを保証できます。
構造と設計上の考慮事項
これらの基本的な概念に基づき、Randflake IDがこれらのアイデアを実際にどのように実装しているかを見ていきましょう。
Randflake IDの構造には、秒単位の精度を持つ30ビットのUnixタイムスタンプ、17ビットのノード識別子、17ビットのローカルカウンター、およびsparx64アルゴリズムに基づく64ビットのブロック暗号が含まれます。
いくつかの設計上の決定事項は以下の通りです。
Google Cloud Platformの一部のVMインスタンスは0.2msの精度でクロックを同期できますが、そのレベルの精度はパブリックインターネットや他のクラウドプロバイダーでは利用できません。
我々は、ノード間のクロックを数ミリ秒の解像度でしか効果的に同期できないため、秒単位の精度を選択しました。
17ビットのノード識別子により、同時に131072個の個別のジェネレーターが可能になり、これらはプロセスごと、コアごと、スレッドごとに割り当てることができます。
高スループットシステムでは、17ビットのローカルカウンターでは不十分な場合があります。スループットを合わせるために、それぞれ異なるノードIDを持つ複数のジェネレーターを単一のプロセスまたはスレッドで動作させることができます。
我々は、現代の軽量ARXベースのブロック暗号であるsparx64を64ビットのブロック暗号として採用しました。
Randflake IDは内部的なトレーサビリティを提供し、秘密鍵を持つ者のみにその発信元ノードIDとタイムスタンプを開示します。
理論上の最大スループットは17,179,869,184 ID/秒であり、ほとんどのグローバルスケールアプリケーションにとって十分です。
Randflake ID生成の擬似コード
Randflake IDの生成プロセスをさらに説明するために、以下のPython擬似コードは簡略化された実装を提供します。
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Sunday, October 27, 2024 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # タイムスタンプ用30ビット(34年の寿命)
10RANDFLAKE_NODE_BITS = 17 # ノードID用17ビット(最大131072ノード)
11RANDFLAKE_SEQUENCE_BITS = 17 # シーケンス用17ビット(最大131072シーケンス)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
ノードIDリースメカニズムを特徴とする、本番環境対応のRandflakeの実装は、GitHubで入手可能です。
その他の考慮事項
このセクションでは、Randflake IDを実装するためのいくつかの追加の考慮事項について議論します。
ノードIDの調整
リースベースのノードID調整を推奨します。
このアプローチでは、中央調整サービスが各ジェネレーターに一意のノードIDを割り当てます。
このノードIDは、一意性を確保するためにリース期間中再割り当てされず、調整サービスとの頻繁な通信の必要性を減らします。
リースを保持しているジェネレーターは、更新条件が満たされている場合、調整サービスにリースの更新を要求できます。
更新条件とは、ジェネレーターがまだアクティブであり、ノードIDを必要としているなど、リースが更新されるために満たされなければならない一連の基準を指します。
リースホルダーは、ノードID範囲の現在の保持者です。
リースは、有効期間内であればアクティブであり、期限切れではありません。
この方法により、リース更新期間ごとに1回のラウンドトリップに削減でき、分散システムにおけるレイテンシを最小限に抑え、効率を向上させることができます。
クロック障害に対する軽減策
リースサービスは、リースを割り当てる際にタイムスタンプの整合性を確認する必要があります。割り当てられたリースの開始時刻は、最後のリースの開始時刻以上でなければなりません。
現在のタイムスタンプがリースの開始時刻よりも小さい場合、またはリースの終了時刻よりも大きい場合、ジェネレーターはリクエストを拒否する必要があります。
この手順は、クロックが逆行した場合に生成されるIDの一意性を保護するために重要です。例えば、クロックが逆行した場合、以前に割り当てられたリースよりも早い開始時刻を持つ新しいリースが割り当てられる可能性があり、重複するIDが生成される可能性があります。既存のリース期間内のタイムスタンプを持つリクエストを拒否することにより、このシナリオを防ぎ、IDの一意性を維持します。
ID分布の均一性
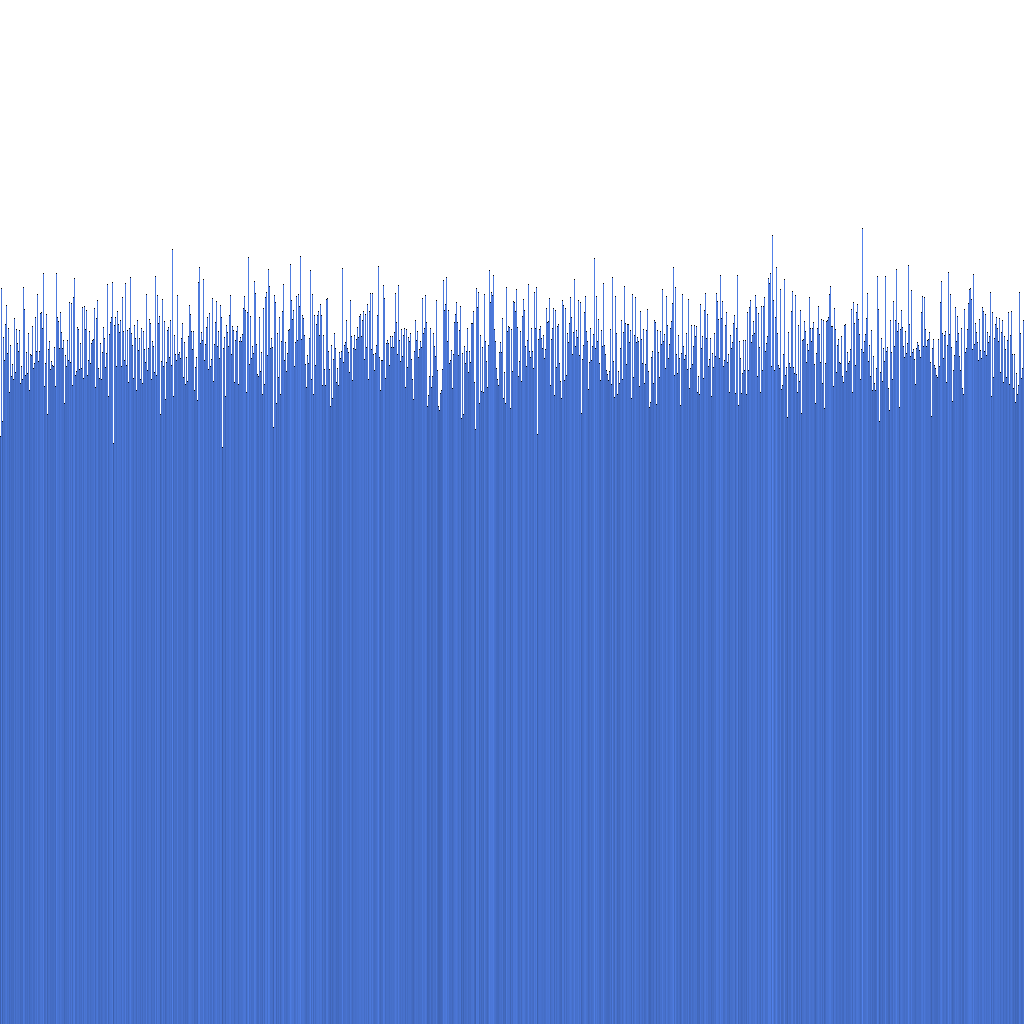
上記のヒストグラムから、生成されたRandflake IDの分布が非常に均一であることがわかります。これは、ID分布をシャーディングキーとして直接使用できることを示唆しています。
結論
この記事では、SnowflakeとSparx64の利点を組み合わせた新しいID生成アルゴリズムであるRandflakeを紹介しました。
この記事が、Randflakeとその実装について包括的な理解を提供できたことを願っています。
Randflakeの完全なソースコードはGitHubで見つけることができます。
ご質問やご提案がございましたら、お気軽にお問い合わせください。また、Randflakeの改善や他のプログラミング言語での実装にご協力いただける貢献者も募集しています。
RandflakeとSnowflake向けのプロダクションレディな調整サービスをリリースする予定であり、GitHubでオープンソース化される予定です。今後の更新にご期待ください!