Randflake ID 소개: 분산형, 균일형, 예측 불가능하며 고유한 무작위 ID 생성기.
고유한 64비트 난수를 생성해야 하며, 외부 당사자가 다음 또는 이전 숫자를 예측할 수 없는 상황을 가정해 봅시다.
여기서 8바이트의 무작위 값을 생성하고, 데이터베이스에 이미 존재하는지 확인한 다음, 고유하다면 저장할 수 있습니다.
그러나 이 방법에는 몇 가지 단점이 있습니다. 고유성을 보장하기 위해 생성된 모든 숫자를 데이터베이스에 저장해야 합니다. 특히 확장성이 중요한 분산 환경에서는 데이터베이스로의 최소 한 번의 왕복 통신이 필요하여 지연 문제가 발생합니다.
이러한 문제들을 해결하기 위해 우리는 분산적이고 균일하며 예측 불가능하고 고유한 무작위 ID 생성기인 Randflake ID를 소개합니다.
Randflake ID는 어떻게 작동하는가?
Randflake ID는 X(이전 Twitter)가 개발한 널리 사용되는 k-sorted ID 생성 메커니즘인 Snowflake ID에서 영감을 받았습니다.
Snowflake ID는 현재 타임스탬프, 노드 ID 및 로컬 카운터를 사용하여 식별자를 생성합니다.
우리는 이 접근 방식을 무작위 고유 ID 생성에 더욱 확장하고 새로운 Secret key 요소를 추가했습니다.
핵심 아이디어는 기존 고유 ID 생성기에 블록 암호 레이어를 추가하여 숫자 간의 관계 예측 불가능성을 달성하는 것입니다.
블록 암호는 고정 길이의 평문 블록을 동일한 길이의 암호문 블록으로 변환하는 기본적인 암호화 함수입니다. 이 변환은 암호화 키에 의해 제어됩니다. 블록 암호의 특징은 가역성입니다. 즉, 단사(bijective) 함수여야 하며, 각 고유 입력이 고유 출력에 대응하고 그 반대도 마찬가지여야 합니다. 이 속성은 복호화에 중요하며, 올바른 키가 적용될 때 암호문에서 원래 평문을 복구할 수 있도록 합니다.
블록 암호를 일대일 함수로 사용함으로써, 정의된 범위 내에서 각 고유 입력이 상응하는 고유 출력을 생성함을 보장할 수 있습니다.
구조 및 설계 고려사항
이러한 기본 개념들을 바탕으로 Randflake ID가 이러한 아이디어들을 실제로 어떻게 구현하는지 살펴보겠습니다.
Randflake ID 구조는 30비트 초 단위 Unix timestamp, 17비트 노드 식별자, 17비트 로컬 카운터, 그리고 sparx64 알고리즘에 기반한 64비트 블록 암호를 포함합니다.
다음은 몇 가지 설계 결정 사항입니다:
Google Cloud Platform의 일부 VM 인스턴스는 0.2ms 정밀도로 클록을 동기화할 수 있지만, 이러한 수준의 정확도는 공용 인터넷이나 다른 클라우드 공급자에서는 사용할 수 없습니다.
우리는 노드 간에 클록을 몇 밀리초 해상도 내에서만 효과적으로 동기화할 수 있기 때문에 초 단위 정밀도를 선택했습니다.
17비트 노드 식별자는 동시에 131072개의 개별 생성기를 허용하며, 이는 프로세스별, 코어별, 스레드별 방식으로 할당될 수 있습니다.
높은 처리량 시스템에서는 17비트 로컬 카운터가 불충분할 수 있습니다. 처리량을 맞추기 위해, 우리는 각각 고유한 노드 ID를 가진 여러 생성기를 단일 프로세스 또는 스레드에서 작동하도록 할당할 수 있습니다.
우리는 현대적인 경량 ARX 기반 블록 암호인 sparx64를 64비트 블록 암호로 채택했습니다.
Randflake ID는 내부 추적성을 제공하며, Secret key를 소유한 사람에게만 원본 노드 ID와 timestamp를 공개합니다.
이론적인 최대 처리량은 17,179,869,184 ID/s이며, 이는 대부분의 글로벌 규모 애플리케이션에 충분합니다.
Randflake ID 생성의 유사 코드
Randflake ID 생성 과정을 더 자세히 설명하기 위해 다음 Python 유사 코드는 단순화된 구현을 제공합니다.
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Sunday, October 27, 2024 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bits for timestamp (lifetime of 34 years)
10RANDFLAKE_NODE_BITS = 17 # 17 bits for node id (max 131072 nodes)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bits for sequence (max 131072 sequences)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
노드 ID 임대 메커니즘을 특징으로 하는 Randflake의 프로덕션 준비 구현은 GitHub에서 확인할 수 있습니다.
기타 고려 사항
이 섹션에서는 Randflake ID 구현을 위한 몇 가지 추가 고려 사항을 논의할 것입니다.
노드 ID 조정
우리는 임대 기반 노드 ID 조정을 제안합니다.
이 접근 방식에서 중앙 조정 서비스는 각 생성기에 고유한 노드 ID를 할당합니다.
이 노드 ID는 고유성을 보장하기 위해 임대 기간 동안 재할당되지 않으므로, 조정 서비스와의 빈번한 통신 필요성을 줄입니다.
임대를 보유한 생성기는 갱신 조건이 충족되면 조정 서비스에 임대 갱신을 요청할 수 있습니다.
갱신 조건은 생성기가 여전히 활성 상태이고 노드 ID를 필요로 하는 등 임대가 갱신되기 위해 충족되어야 하는 일련의 기준을 의미합니다.
임대 보유자는 노드 ID 범위의 현재 소유자입니다.
임대는 유효 기간 내에 있다면 활성 상태이며 만료되지 않은 것으로 간주됩니다.
이러한 방식으로, 우리는 임대 갱신 기간당 한 번의 왕복 통신으로 왕복 횟수를 줄여 분산 시스템에서 지연 시간을 최소화하고 효율성을 향상시킬 수 있습니다.
잘못된 클록에 대한 완화
임대 서비스는 임대를 할당할 때 타임스탬프 일관성을 확인해야 합니다. 할당된 임대 시작 시간은 마지막 임대 시작 시간보다 크거나 같아야 합니다.
생성기는 현재 타임스탬프가 임대 시작 시간보다 작거나 임대 종료 시간보다 크면 요청을 거부해야 합니다.
이 절차는 클록이 뒤로 점프할 때 생성된 ID의 고유성을 보호하는 데 중요합니다. 예를 들어, 클록이 뒤로 점프하면 이전에 할당된 임대보다 더 이른 시작 시간으로 새 임대가 할당될 수 있으며, 이는 잠재적으로 중복 ID가 생성되는 결과를 초래할 수 있습니다. 기존 임대 기간 내의 타임스탬프를 가진 요청을 거부함으로써 우리는 이 시나리오를 방지하고 ID의 고유성을 유지합니다.
ID 분포의 균일성
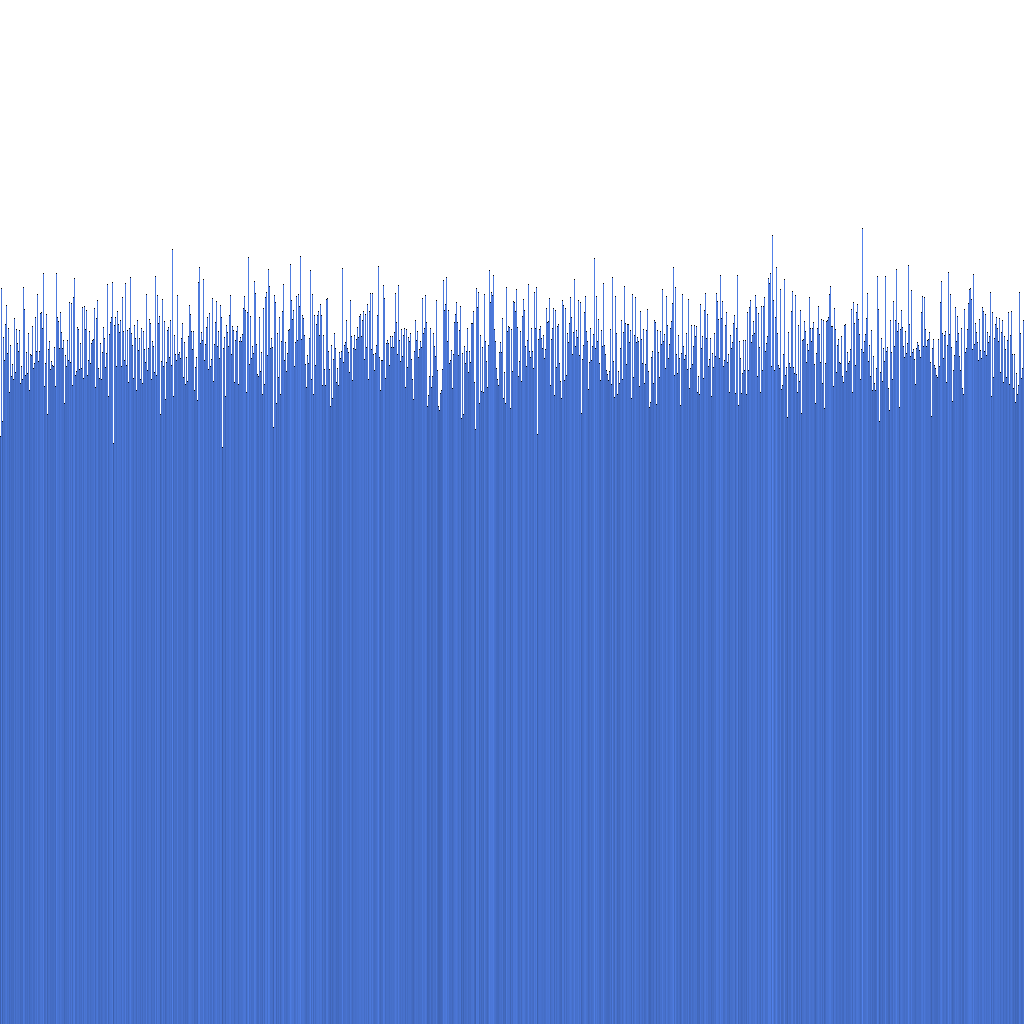
위 히스토그램을 기반으로 우리는 생성된 Randflake ID의 분포가 매우 균일함을 알 수 있습니다. 이는 ID 분포가 샤딩 키로 직접 사용될 수 있음을 시사합니다.
결론
이 글에서 우리는 Snowflake와 Sparx64의 장점을 결합한 새로운 ID 생성 알고리즘인 Randflake를 소개했습니다.
이 글이 Randflake와 그 구현에 대한 포괄적인 이해를 제공했기를 바랍니다.
Randflake의 전체 소스 코드는 GitHub에서 찾을 수 있습니다.
질문이나 제안이 있으시면 언제든지 문의해 주십시오. 또한 Randflake를 개선하고 다른 프로그래밍 언어로 구현하는 데 도움을 줄 기여자들을 찾고 있습니다.
우리는 Randflake 및 Snowflake를 위한 프로덕션 준비 조정 서비스를 출시할 계획이며, 이는 GitHub에 오픈 소스로 공개될 것입니다. 업데이트를 기대해 주십시오!