Introductie van Randflake ID: een gedistribueerde, uniforme, onvoorspelbare, unieke willekeurige ID-generator.
Overweeg een situatie waarin we unieke 64-bit willekeurige getallen moeten genereren, en externe partijen niet in staat mogen zijn om het volgende of vorige getal te voorspellen.
Hier kunnen we een 8-byte willekeurige waarde genereren, controleren of deze al bestaat in de database, en deze vervolgens opslaan als deze uniek is.
Deze methode heeft echter verschillende nadelen. We moeten elk gegenereerd getal in een database opslaan om uniciteit te waarborgen. De vereiste van ten minste één round trip naar de database creëert latency-problemen, vooral in een gedistribueerde omgeving waar schaalbaarheid cruciaal is.
Om deze problemen op te lossen, introduceren we Randflake ID: een gedistribueerde, uniforme, onvoorspelbare, unieke willekeurige ID-generator.
Hoe werkt Randflake ID?
Randflake ID is geïnspireerd op Snowflake ID, het veelgebruikte k-gesorteerde ID-generatiemechanisme ontwikkeld door X (voorheen Twitter).
Snowflake ID gebruikt de huidige timestamp, een node ID en een lokale teller om een identificatie te genereren.
We hebben deze benadering verder uitgebreid voor het genereren van willekeurige unieke ID's en een nieuw geheim sleutelelement toegevoegd.
Het kernidee is het toevoegen van een blokcijferlaag aan de bestaande unieke ID-generator om de onmogelijkheid te bereiken om de relatie tussen getallen te voorspellen.
Een blokcijfer is een fundamentele cryptografische functie die een blok platte tekst met een vaste lengte transformeert in een blok cijfertekst van dezelfde lengte. Deze transformatie wordt beheerst door een cryptografische sleutel. Het onderscheidende kenmerk van een blokcijfer is de omkeerbaarheid: het moet een één-op-één (bijectieve) functie zijn, wat garandeert dat elke unieke invoer correspondeert met een unieke uitvoer, en vice versa. Deze eigenschap is cruciaal voor decryptie, waardoor de originele platte tekst kan worden hersteld uit de cijfertekst wanneer de juiste sleutel wordt toegepast.
Door een blokcijfer als een één-op-één functie te gebruiken, kunnen we garanderen dat elke unieke invoer een corresponderende unieke uitvoer produceert binnen het gedefinieerde bereik.
De structuur en ontwerpoverweging
Voortbouwend op deze fundamentele concepten, laten we onderzoeken hoe Randflake ID deze ideeën in de praktijk implementeert.
De Randflake ID-structuur omvat een 30-bit Unix-timestamp met seconde precisie, een 17-bit node identifier, een 17-bit lokale teller en een 64-bit blokcijfer gebaseerd op het sparx64-algoritme.
Hier zijn enkele ontwerpbeslissingen:
Sommige VM-instanties in Google Cloud Platform kunnen de klok synchroniseren met een precisie van 0,2 ms, maar dat nauwkeurigheidsniveau is niet beschikbaar op het openbare internet of bij andere cloudproviders.
We hebben gekozen voor een seconde precisie omdat we de klok tussen nodes effectief kunnen synchroniseren binnen enkele milliseconden resolutie.
Een 17-bit node identifier maakt 131072 individuele generatoren op hetzelfde moment mogelijk, die per-proces, per-core, per-thread kunnen worden toegewezen.
In systemen met hoge doorvoer kan een 17-bit lokale teller onvoldoende zijn. Om de doorvoer te evenaren, kunnen we meerdere generatoren, elk met een onderscheiden node ID, toewijzen om in een enkel proces of thread te werken.
We hebben sparx64 geadopteerd als een 64-bit blokcijfer, een modern lichtgewicht ARX-gebaseerd blokcijfer.
Randflake ID's bieden interne traceerbaarheid, waarbij hun oorspronkelijke node ID en timestamp alleen worden onthuld aan degenen die de geheime sleutel bezitten.
De theoretische maximale doorvoer bedraagt 17.179.869.184 ID/s, wat voldoende is voor de meeste wereldwijde toepassingen.
Pseudocode van Randflake ID-generatie
Om het Randflake ID-generatieproces verder te illustreren, biedt de volgende Python-pseudocode een vereenvoudigde implementatie:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Zondag 27 oktober 2024 3:33:20 AM UTC
7
8# Bits allocatie
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bits voor timestamp (levensduur van 34 jaar)
10RANDFLAKE_NODE_BITS = 17 # 17 bits voor node id (max 131072 nodes)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bits voor sequence (max 131072 sequences)
12
13# Afgeleide constanten
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Een productieklare implementatie van Randflake, met een node ID lease-mechanisme, is beschikbaar op GitHub.
Overige overwegingen
In deze sectie bespreken we enkele aanvullende overwegingen voor het implementeren van Randflake ID.
Coördinatie van Node ID
Wij stellen lease-gebaseerde Node ID-coördinatie voor.
Bij deze aanpak wijst een centrale coördinatiedienst een unieke node ID toe aan elke generator.
Dit node ID wordt niet opnieuw toegewezen gedurende de leaseperiode om uniciteit te waarborgen, waardoor de behoefte aan frequente communicatie met de coördinatiedienst wordt verminderd.
De generator die de lease bezit, kan een verlenging van de lease aanvragen bij de coördinatiedienst als aan de verlengingsvoorwaarde is voldaan.
De verlengingsvoorwaarde verwijst naar een reeks criteria waaraan moet worden voldaan voor de verlenging van de lease, zoals dat de generator nog steeds actief is en het node ID nodig heeft.
De leasehouder is de huidige houder van het node ID-bereik.
De lease wordt als actief en niet verlopen beschouwd als deze binnen de geldige tijdsperiode valt.
Op deze manier kunnen we round trips beperken tot één per leaseverlengingsperiode, waardoor latency wordt geminimaliseerd en de efficiëntie in gedistribueerde systemen wordt verbeterd.
Mitigatie tegen een defecte klok
De leaseservice moet de consistentie van de tijdstempels controleren bij het toewijzen van een lease. De toegewezen starttijd van de lease moet groter zijn dan of gelijk zijn aan de starttijd van de laatste lease.
De generator moet het verzoek afwijzen als de huidige timestamp kleiner is dan de starttijd van de lease of groter is dan de eindtijd van de lease.
Deze procedure is belangrijk om de uniciteit van gegenereerde ID's te beschermen wanneer de klok terugspringt. Bijvoorbeeld, als een klok terugspringt, zou een nieuwe lease kunnen worden toegewezen met een starttijd die eerder is dan een eerder toegewezen lease, wat potentieel kan leiden tot het genereren van dubbele ID's. Door verzoeken met tijdstempels binnen een bestaande leaseperiode af te wijzen, voorkomen we dit scenario en handhaven we de uniciteit van de ID's.
Uniformiteit van ID-distributie
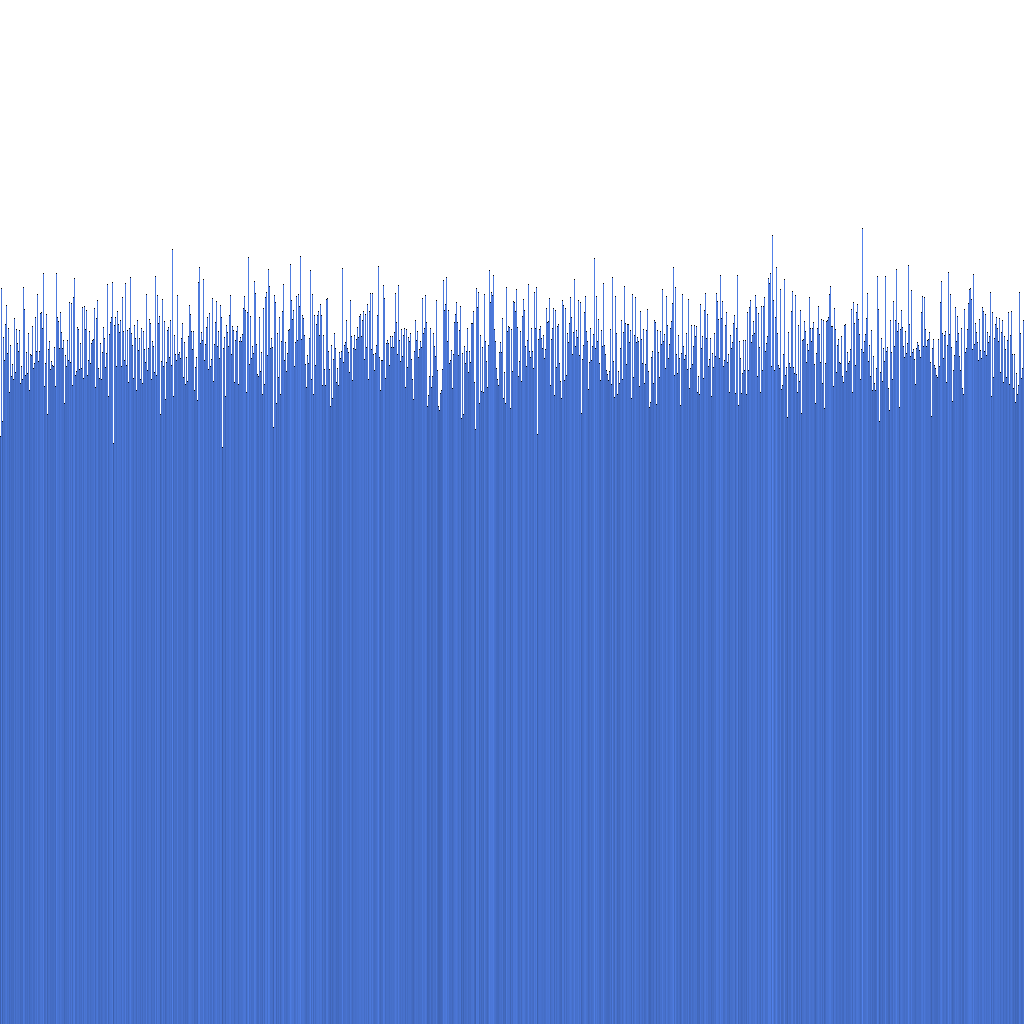
Op basis van het bovenstaande histogram kunnen we zien dat de distributie van gegenereerde Randflake ID's zeer uniform is. Dit suggereert dat de ID-distributie direct kan worden gebruikt als een sharding key.
Conclusie
In dit artikel hebben we Randflake geïntroduceerd, een nieuw algoritme voor ID-generatie dat de voordelen van Snowflake en Sparx64 combineert.
Wij hopen dat dit artikel u een uitgebreid begrip heeft gegeven van Randflake en de implementatie ervan.
De volledige broncode voor Randflake kunt u vinden op GitHub.
Als u vragen of suggesties heeft, aarzel dan niet om contact op te nemen. We zijn ook op zoek naar bijdragers om Randflake te verbeteren en in andere programmeertalen te implementeren.
We zijn van plan om een productieklare coördinatiedienst voor Randflake en Snowflake uit te brengen, die als open-source op GitHub beschikbaar zal worden gesteld. Blijf op de hoogte voor updates!