Introduksjon av Randflake ID: en distribuert, uniform, uforutsigbar, unik generator for tilfeldige ID-er.
Betrakt en situasjon der vi trenger å generere unike 64-bit tilfeldige tall, og eksterne parter ikke skal kunne forutsi det neste eller forrige tallet.
Her kan vi generere en 8-byte tilfeldig verdi, sjekke om den allerede eksisterer i databasen, og deretter lagre den hvis den er unik.
Denne metoden har imidlertid flere ulemper. Vi må lagre hvert generert tall i en database for å sikre unikhet. Kravet om minst én tur-retur til databasen skaper forsinkelsesproblemer, spesielt i et distribuert miljø der skalerbarhet er avgjørende.
For å løse disse problemene introduserer vi Randflake ID: en distribuert, uniform, uforutsigbar, unik random ID-generator.
Hvordan fungerer Randflake ID?
Randflake ID er inspirert av Snowflake ID, den mye brukte k-sorterte ID-genereringsmekanismen utviklet av X (tidligere twitter).
Snowflake ID bruker gjeldende tidsstempel, en node ID og en lokal teller for å generere en identifikator.
Vi utvidet denne tilnærmingen ytterligere for generering av tilfeldige unike ID-er og la til et nytt hemmelig nøkkelelement.
Nøkkelideen er å legge til et blokkchifferlag til den eksisterende unike ID-generatoren for å oppnå umulighet i å forutsi forholdet mellom tall.
Et blokkchiffer er en fundamental kryptografisk funksjon som transformerer en blokk med klartekst av fast lengde til en blokk med chiffertekst av samme lengde. Denne transformasjonen styres av en kryptografisk nøkkel. Den særpregede egenskapen til et blokkchiffer er dets reversibilitet: det må være en en-til-en (bijektiv) funksjon, som sikrer at hver unike inngang tilsvarer en unik utgang, og omvendt. Denne egenskapen er avgjørende for dekryptering, da den gjør det mulig å gjenopprette den opprinnelige klarteksten fra chifferteksten når riktig nøkkel brukes.
Ved å anvende et blokkchiffer som en en-til-en-funksjon, kan vi garantere at hver unike inngang produserer en tilsvarende unik utgang innenfor det definerte området.
Struktur og designhensyn
Basert på disse grunnleggende konseptene, la oss undersøke hvordan Randflake ID implementerer disse ideene i praksis.
Randflake ID-strukturen inkluderer et 30-bit unix timestamp med sekundpresisjon, en 17-bit node identifier, en 17-bit local counter, og et 64-bit block cipher basert på sparx64-algoritmen.
Her er noen designbeslutninger:
Noen VM-instanser i Google Cloud Platform kan synkronisere klokken med 0.2ms presisjon, men det nivået av nøyaktighet er ikke tilgjengelig på offentlig internett eller andre skyleverandører.
Vi valgte en sekundpresisjon fordi vi effektivt kan synkronisere klokken mellom noder kun innenfor noen få millisekunders oppløsninger.
17-bit node identifier tillater 131072 individuelle generatorer samtidig, som kan tildeles per-prosess, per-kjerne, per-tråd.
I systemer med høy gjennomstrømning kan en 17-bit local counter være utilstrekkelig. For å matche gjennomstrømningen kan vi tildele flere generatorer, hver med en distinkt node ID, til å arbeide i en enkelt prosess eller tråd.
Vi adopterte sparx64 som et 64-bit block cipher, et moderne lettvekts ARX-basert block cipher.
Randflake ID-er tilbyr intern sporbarhet, og avslører deres opprinnelige node ID og tidsstempel kun for de som besitter den hemmelige nøkkelen.
Teoretisk maksimal gjennomstrømning er 17 179 869 184 ID/s, noe som er tilstrekkelig for de fleste globale applikasjoner.
Pseudokode for Randflake ID-generering
For å ytterligere illustrere Randflake ID-genereringsprosessen, gir følgende Python-pseudokode en forenklet implementasjon:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Søndag, 27. oktober 2024 03:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bits for tidsstempel (levetid på 34 år)
10RANDFLAKE_NODE_BITS = 17 # 17 bits for node-ID (maks 131072 noder)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bits for sekvens (maks 131072 sekvenser)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
En produksjonsklar implementasjon av Randflake, med en node ID lease-mekanisme, er tilgjengelig på GitHub.
Andre betraktninger
I denne seksjonen vil vi diskutere noen ytterligere betraktninger for implementering av Randflake ID.
Node ID-koordinering
Vi foreslår lease-basert node ID-koordinering.
I denne tilnærmingen tildeler en sentral koordineringstjeneste en unik node ID til hver generator.
Denne node-ID-en tildeles ikke på nytt i løpet av leieperioden for å sikre unikhet, noe som reduserer behovet for hyppig kommunikasjon med koordineringstjenesten.
Generatoren som holder leieavtalen kan be om en fornyelse av leieavtalen fra koordineringstjenesten hvis fornyelsesbetingelsen er oppfylt.
Fornyelsesbetingelsen refererer til et sett med kriterier som må oppfylles for at leieavtalen skal fornyes, for eksempel at generatoren fortsatt er aktiv og krever node-ID-en.
Leietakeren er den nåværende innehaveren av node-ID-området.
Leieavtalen anses som aktiv og ikke utløpt hvis den er innenfor sin gyldige tidsperiode.
På denne måten kan vi redusere rundturstider til én per leiefornyelsesperiode, noe som minimerer latens og forbedrer effektiviteten i distribuerte systemer.
Avbøtning mot feilaktig klokke
Leasetjenesten må sjekke tidsstempelkonsistens ved tildeling av en lease. Den tildelte leasestarttiden må være større enn eller lik den siste leasestarttiden.
Generatoren skal avvise forespørselen hvis gjeldende tidsstempel er mindre enn leasestarttiden eller større enn leaseendringstiden.
Denne prosedyren er viktig for å beskytte unikheten til genererte ID-er når klokken hopper bakover. For eksempel, hvis en klokke hopper bakover, kan en ny lease tildeles med en starttid tidligere enn en tidligere tildelt lease, noe som potensielt kan føre til at duplikate ID-er genereres. Ved å avvise forespørsler med tidsstempler innenfor en eksisterende leaseperiode, forhindrer vi dette scenariet og opprettholder unikheten til ID-ene.
Ensartethet i ID-distribusjon
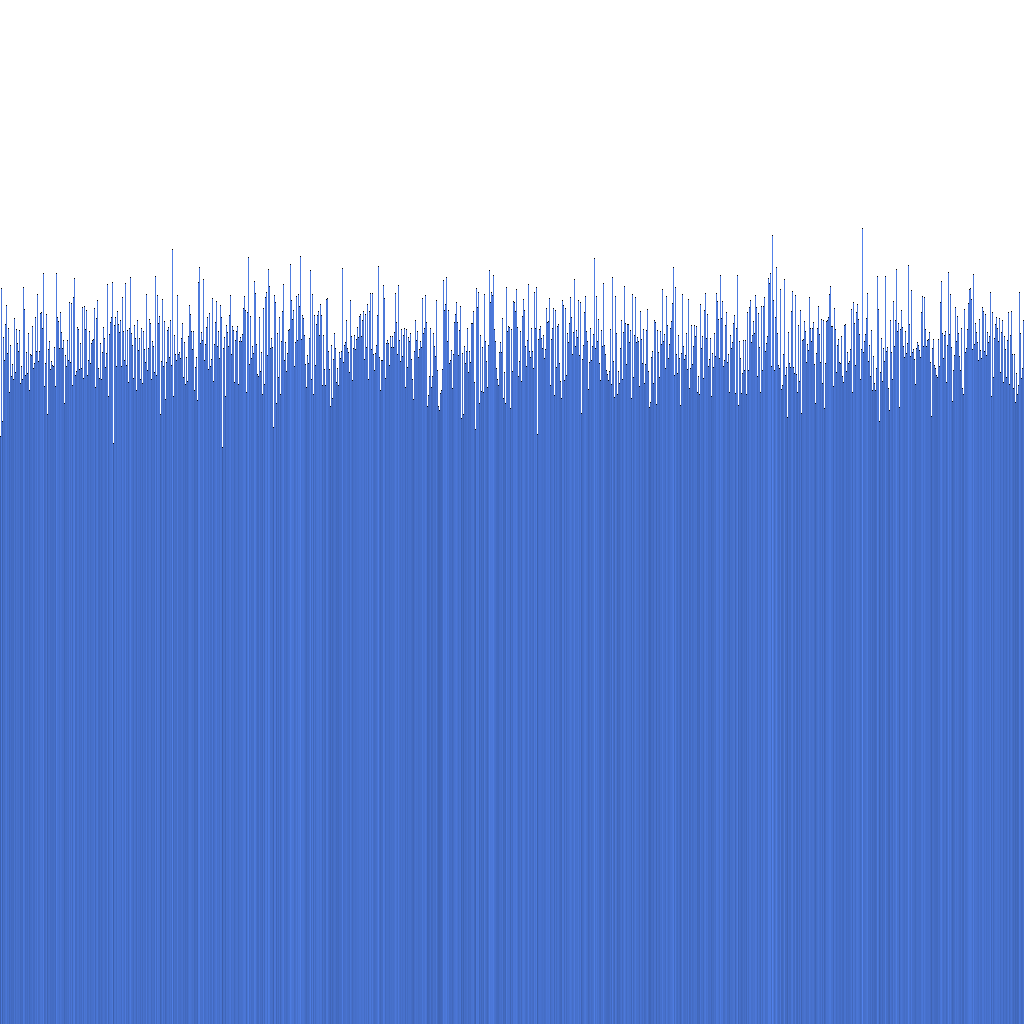
Basert på histogrammet ovenfor kan vi se at distribusjonen av genererte Randflake ID-er er svært ensartet. Dette antyder at ID-distribusjonen kan brukes direkte som en sharding key.
Konklusjon
I denne artikkelen introduserte vi Randflake, en ny ID-generasjonsalgoritme som kombinerer fordelene med Snowflake og Sparx64.
Vi håper denne artikkelen har gitt deg en omfattende forståelse av Randflake og dens implementering.
Du finner hele kildekoden for Randflake på GitHub.
Hvis du har spørsmål eller forslag, ikke nøl med å ta kontakt. Vi søker også bidragsytere for å hjelpe til med å forbedre Randflake og implementere det i andre programmeringsspråk.
Vi planlegger å lansere en produksjonsklar koordineringstjeneste for Randflake og Snowflake, som vil bli åpen kildekode på GitHub. Følg med for oppdateringer!