Zwiększanie responsywności za pomocą buforowania po stronie klienta Redis
Czym jest Redis?
Sądzę, że niewiele osób nie zna Redis. Niemniej jednak, pozwolę sobie krótko podsumować jego kilka cech:
- Operacje są wykonywane w pojedynczym wątku, co zapewnia atomowość wszystkich operacji.
- Dane są przechowywane i przetwarzane In-Memory, co sprawia, że wszystkie operacje są szybkie.
- Redis może, w zależności od opcji, przechowywać WAL, co umożliwia szybkie tworzenie kopii zapasowych i odzyskiwanie najnowszego stanu.
- Obsługuje wiele typów danych, takich jak Set, Hash, Bit, List, co zapewnia wysoką produktywność.
- Posiada dużą społeczność, co umożliwia dzielenie się różnorodnymi doświadczeniami, problemami i rozwiązaniami.
- Jest rozwijany i eksploatowany przez długi czas, co gwarantuje niezawodną stabilność.
Przechodząc do sedna
Wyobraź sobie?
Co by było, gdyby pamięć podręczna Twojej usługi spełniała następujące dwa warunki?
- Często przeglądane dane muszą być dostarczane użytkownikowi w najnowszym stanie, ale aktualizacje są nieregularne, co wymaga częstego odświeżania pamięci podręcznej.
- Aktualizacja nie jest możliwa, ale konieczny jest częsty dostęp do tych samych danych w pamięci podręcznej w celu ich odczytu.
W pierwszym przypadku można rozważyć ranking popularności w czasie rzeczywistym w sklepie internetowym. Gdy ranking popularności w czasie rzeczywistym w sklepie internetowym jest przechowywany jako sorted set, nieefektywne jest odczytywanie go z Redis za każdym razem, gdy użytkownik uzyskuje dostęp do strony głównej. W drugim przypadku, w odniesieniu do danych kursów walut, nawet jeśli dane kursów walut są ogłaszane w przybliżeniu co 10 minut, faktyczne zapytania są bardzo częste. Ponadto, w przypadku walut won-dolar, won-jen, won-juan, pamięć podręczna jest bardzo często sprawdzana. W takich przypadkach, efektywnym działaniem byłoby, aby serwer API posiadał oddzielną lokalną pamięć podręczną, a po zmianie danych odpytywał Redis w celu ich odświeżenia.
Jak zatem zaimplementować takie działanie w architekturze baza danych - Redis - serwer API?
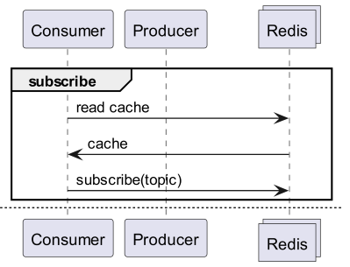
Czy Redis PubSub nie wystarczy?
Subskrybuj kanał, aby otrzymywać powiadomienia o aktualizacji pamięci podręcznej!
- Należy wówczas stworzyć logikę wysyłania wiadomości w momencie aktualizacji.
- Dodatkowe operacje wynikające z PubSub wpływają na wydajność.
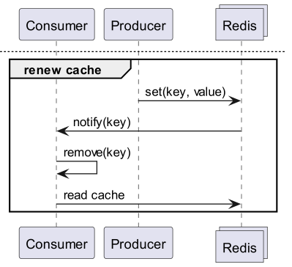
Co jeśli Redis wykryje zmiany?
Czy użycie Keyspace Notification w celu otrzymywania powiadomień o poleceniach dla danego klucza?
- Istnieje uciążliwość związana z koniecznością wcześniejszego przechowywania i udostępniania kluczy i poleceń używanych do aktualizacji.
- Na przykład, dla niektórych kluczy aktualizacją jest proste Set, dla innych LPush, RPush, SAdd lub SRem, co staje się skomplikowane.
- To znacznie zwiększa prawdopodobieństwo błędów komunikacyjnych i błędów ludzkich w kodowaniu podczas procesu deweloperskiego.
Czy użycie Keyevent Notification w celu otrzymywania powiadomień na poziomie polecenia?
- Wymaga to subskrybowania wszystkich poleceń używanych do aktualizacji. Konieczne jest odpowiednie filtrowanie kluczy, które z nich pochodzą.
- Na przykład, dla niektórych kluczy przychodzących z Del, dany klient prawdopodobnie nie posiada lokalnej pamięci podręcznej.
- Może to prowadzić do niepotrzebnego marnowania zasobów.
Dlatego potrzebne jest Invalidation Message!
Czym jest Invalidation Message?
Invalidation Messages to koncepcja wprowadzona w Redis 6.0 jako część Server Assisted Client-Side Cache. Invalidation Message jest dostarczana w następującym schemacie:
- Zakłada się, że ClientB już raz odczytał key.
- ClientA ustawia nowy key.
- Redis wykrywa zmianę i wysyła Invalidation Message do ClientB, informując go o konieczności usunięcia pamięci podręcznej.
- ClientB otrzymuje tę wiadomość i podejmuje odpowiednie działania.
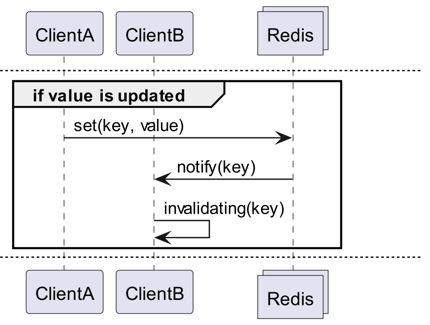
Jak tego używać
Podstawowa struktura działania
Klient podłączony do Redis wykonuje CLIENT TRACKING ON REDIRECT <client-id>, aby odbierać Invalidation Message. Klient, który ma odbierać wiadomości, subskrybuje SUBSCRIBE __redis__:invalidate, aby odbierać Invalidation Message.
default tracking
1# client 1
2> SET a 100
1# client 3
2> CLIENT ID
312
4> SUBSCRIBE __redis__:invalidate
51) "subscribe"
62) "__redis__:invalidate"
73) (integer) 1
1# client 2
2> CLIENT TRACKING ON REDIRECT 12
3> GET a # tracking
1# client 1
2> SET a 200
1# client 3
21) "message"
32) "__redis__:invalidate"
43) 1) "a"
broadcasting tracking
1# client 3
2> CLIENT ID
312
4> SUBSCRIBE __redis__:invalidate
51) "subscribe"
62) "__redis__:invalidate"
73) (integer) 1
1# client 2
2CLIENT TRACKING ON BCAST PREFIX cache: REDIRECT 12
1# client 1
2> SET cache:name "Alice"
3> SET cache:age 26
1# client 3
21) "message"
32) "__redis__:invalidate"
43) 1) "cache:name"
51) "message"
62) "__redis__:invalidate"
73) 1) "cache:age"
Implementacja! Implementacja! Implementacja!
Redigo + Ristretto
Samo takie wyjaśnienie może sprawić, że będzie niejasne, jak tego używać w rzeczywistym kodzie. Dlatego najpierw skonfigurujemy to za pomocą redigo i ristretto.
Najpierw zainstaluj dwie zależności:
github.com/gomodule/redigogithub.com/dgraph-io/ristretto
1package main
2
3import (
4 "context"
5 "fmt"
6 "log/slog"
7 "time"
8
9 "github.com/dgraph-io/ristretto"
10 "github.com/gomodule/redigo/redis"
11)
12
13type RedisClient struct {
14 conn redis.Conn
15 cache *ristretto.Cache[string, any]
16 addr string
17}
18
19func NewRedisClient(addr string) (*RedisClient, error) {
20 cache, err := ristretto.NewCache(&ristretto.Config[string, any]{
21 NumCounters: 1e7, // liczba kluczy do śledzenia częstotliwości (10M).
22 MaxCost: 1 << 30, // maksymalny koszt pamięci podręcznej (1GB).
23 BufferItems: 64, // liczba kluczy na bufor Get.
24 })
25 if err != nil {
26 return nil, fmt.Errorf("failed to generate cache: %w", err)
27 }
28
29 conn, err := redis.Dial("tcp", addr)
30 if err != nil {
31 return nil, fmt.Errorf("failed to connect to redis: %w", err)
32 }
33
34 return &RedisClient{
35 conn: conn,
36 cache: cache,
37 addr: addr,
38 }, nil
39}
40
41func (r *RedisClient) Close() error {
42 err := r.conn.Close()
43 if err != nil {
44 return fmt.Errorf("failed to close redis connection: %w", err)
45 }
46
47 return nil
48}
Najpierw tworzymy prosty RedisClient zawierający ristretto i redigo.
1func (r *RedisClient) Tracking(ctx context.Context) error {
2 psc, err := redis.Dial("tcp", r.addr)
3 if err != nil {
4 return fmt.Errorf("failed to connect to redis: %w", err)
5 }
6
7 clientId, err := redis.Int64(psc.Do("CLIENT", "ID"))
8 if err != nil {
9 return fmt.Errorf("failed to get client id: %w", err)
10 }
11 slog.Info("client id", "id", clientId)
12
13 subscriptionResult, err := redis.String(r.conn.Do("CLIENT", "TRACKING", "ON", "REDIRECT", clientId))
14 if err != nil {
15 return fmt.Errorf("failed to enable tracking: %w", err)
16 }
17 slog.Info("subscription result", "result", subscriptionResult)
18
19 if err := psc.Send("SUBSCRIBE", "__redis__:invalidate"); err != nil {
20 return fmt.Errorf("failed to subscribe: %w", err)
21 }
22 psc.Flush()
23
24 for {
25 msg, err := psc.Receive()
26 if err != nil {
27 return fmt.Errorf("failed to receive message: %w", err)
28 }
29
30 switch msg := msg.(type) {
31 case redis.Message:
32 slog.Info("received message", "channel", msg.Channel, "data", msg.Data)
33 key := string(msg.Data)
34 r.cache.Del(key)
35 case redis.Subscription:
36 slog.Info("subscription", "kind", msg.Kind, "channel", msg.Channel, "count", msg.Count)
37 case error:
38 return fmt.Errorf("error: %w", msg)
39 case []interface{}:
40 if len(msg) != 3 || string(msg[0].([]byte)) != "message" || string(msg[1].([]byte)) != "__redis__:invalidate" {
41 slog.Warn("unexpected message", "message", msg)
42 continue
43 }
44
45 contents := msg[2].([]interface{})
46 keys := make([]string, len(contents))
47 for i, key := range contents {
48 keys[i] = string(key.([]byte))
49 r.cache.Del(keys[i])
50 }
51 slog.Info("received invalidation message", "keys", keys)
52 default:
53 slog.Warn("unexpected message", "type", fmt.Sprintf("%T", msg))
54 }
55 }
56}
Kod jest nieco skomplikowany.
- Aby wykonać Tracking, nawiązywane jest dodatkowe połączenie. Jest to działanie podjęte z uwzględnieniem, że PubSub może zakłócać inne operacje.
- Identyfikator nowo utworzonego połączenia jest pobierany, a następnie Tracking na połączeniu, które ma pobierać dane, jest przekierowywany do tego połączenia.
- Następnie subskrybowane są Invalidation Message.
- Kod obsługujący subskrypcję jest nieco skomplikowany. Ponieważ redigo nie obsługuje parsowania wiadomości unieważniających, konieczne jest odebranie nieprzetworzonej odpowiedzi i jej przetworzenie.
1func (r *RedisClient) Get(key string) (any, error) {
2 val, found := r.cache.Get(key)
3 if found {
4 switch v := val.(type) {
5 case int64:
6 slog.Info("cache hit", "key", key)
7 return v, nil
8 default:
9 slog.Warn("unexpected type", "type", fmt.Sprintf("%T", v))
10 }
11 }
12 slog.Info("cache miss", "key", key)
13
14 val, err := redis.Int64(r.conn.Do("GET", key))
15 if err != nil {
16 return nil, fmt.Errorf("failed to get key: %w", err)
17 }
18
19 r.cache.SetWithTTL(key, val, 1, 10*time.Second)
20 return val, nil
21}
Wiadomość Get najpierw sprawdza ristretto, a jeśli nie znajdzie, pobiera ją z Redis.
1package main
2
3import (
4 "context"
5 "log/slog"
6 "os"
7 "os/signal"
8 "time"
9)
10
11func main() {
12 ctx, cancel := signal.NotifyContext(context.Background(), os.Interrupt)
13 defer cancel()
14
15 client, err := NewRedisClient("localhost:6379")
16 if err != nil {
17 panic(err)
18 }
19 defer client.Close()
20
21 go func() {
22 if err := client.Tracking(ctx); err != nil {
23 slog.Error("failed to track invalidation message", "error", err)
24 }
25 }()
26
27 ticker := time.NewTicker(1 * time.Second)
28 defer ticker.Stop()
29 done := ctx.Done()
30
31 for {
32 select {
33 case <-done:
34 slog.Info("shutting down")
35 return
36 case <-ticker.C:
37 v, err := client.Get("key")
38 if err != nil {
39 slog.Error("failed to get key", "error", err)
40 return
41 }
42 slog.Info("got key", "value", v)
43 }
44 }
45}
Powyżej przedstawiono kod do testowania. Po przetestowaniu można zauważyć, że Redis odświeża wartości za każdym razem, gdy dane są aktualizowane.
Jednak jest to zbyt skomplikowane. Co więcej, aby skalować do klastra, nieuchronnie konieczne jest włączenie Tracking dla wszystkich masterów lub replik.
Rueidis
Biorąc pod uwagę, że używamy języka Go, mamy do dyspozycji najbardziej nowoczesny i zaawansowany rueidis. Napiszmy kod, który wykorzystuje Server Assisted Client Side Cache w środowisku klastra Redis za pomocą rueidis.
Najpierw zainstaluj zależności.
github.com/redis/rueidis
Następnie napisz kod do pobierania danych z Redis.
1package main
2
3import (
4 "context"
5 "log/slog"
6 "os"
7 "os/signal"
8 "time"
9
10 "github.com/redis/rueidis"
11)
12
13func main() {
14 ctx, cancel := signal.NotifyContext(context.Background(), os.Interrupt)
15 defer cancel()
16
17 client, err := rueidis.NewClient(rueidis.ClientOption{
18 InitAddress: []string{"localhost:6379"},
19 })
20 if err != nil {
21 panic(err)
22 }
23
24 ticker := time.NewTicker(1 * time.Second)
25 defer ticker.Stop()
26 done := ctx.Done()
27
28 for {
29 select {
30 case <-done:
31 slog.Info("shutting down")
32 return
33 case <-ticker.C:
34 const key = "key"
35 resp := client.DoCache(ctx, client.B().Get().Key(key).Cache(), 10*time.Second)
36 if resp.Error() != nil {
37 slog.Error("failed to get key", "error", resp.Error())
38 continue
39 }
40 i, err := resp.AsInt64()
41 if err != nil {
42 slog.Error("failed to convert response to int64", "error", err)
43 continue
44 }
45 switch resp.IsCacheHit() {
46 case true:
47 slog.Info("cache hit", "key", key)
48 case false:
49 slog.Info("missed key", "key", key)
50 }
51 slog.Info("got key", "value", i)
52 }
53 }
54}
W rueidis, aby użyć Client Side Cache, wystarczy wywołać DoCache. Następnie dodaje się do lokalnej pamięci podręcznej, określając, jak długo ma być przechowywana, a następnie, wywołując DoCache ponownie, pobiera dane z lokalnej pamięci podręcznej. Oczywiście, wiadomości unieważniające są również prawidłowo obsługiwane.
Dlaczego nie redis-go?
Niestety, redis-go nie obsługuje oficjalnie Server Assisted Client Side Cache. Co więcej, podczas tworzenia PubSub, tworzy nowe połączenie, ale nie ma API do bezpośredniego dostępu do tego połączenia, więc nie można poznać identyfikatora klienta. Z tego powodu uznano, że konfiguracja redis-go jest niemożliwa i została ona pominięta.
To jest sexy
Dzięki strukturze Client Side Cache
- Jeśli dane mogą być przygotowane z wyprzedzeniem, ta struktura może zminimalizować zapytania i ruch do Redis, zawsze dostarczając najnowsze dane.
- Dzięki temu można stworzyć rodzaj struktury CQRS, aby radykalnie zwiększyć wydajność odczytu.

Jak bardzo stało się to bardziej sexy?
W rzeczywistości, ponieważ taka struktura jest już używana w praktyce, sprawdziłem proste opóźnienia dla dwóch interfejsów API. Proszę wybaczyć, że mogę to opisać tylko w bardzo abstrakcyjny sposób.
- Pierwsze API
- Pierwsze zapytanie: średnio 14.63ms
- Kolejne zapytania: średnio 2.82ms
- Średnia różnica: 10.98ms
- Drugie API
- Pierwsze zapytanie: średnio 14.05ms
- Kolejne zapytania: średnio 1.60ms
- Średnia różnica: 11.57ms
Nastąpiła dodatkowa poprawa opóźnień o nawet 82%!
Spodziewane są następujące ulepszenia:
- Pominięcie procesu komunikacji sieciowej między klientem a Redis oraz oszczędność ruchu.
- Zmniejszenie liczby poleceń odczytu, które musi wykonać sam Redis.
- Ma to również wpływ na zwiększenie wydajności zapisu.
- Minimalizacja parsowania protokołu Redis.
- Parsowanie protokołu Redis również nie jest darmowe. Zmniejszenie tego jest dużą szansą.
Jednak wszystko wiąże się z kompromisami. W tym celu poświęciliśmy co najmniej dwie rzeczy:
- Konieczność implementacji, obsługi i utrzymania elementów zarządzania pamięcią podręczną po stronie klienta.
- Zwiększone zużycie CPU i pamięci przez klienta z tego powodu.
Wniosek
Osobiście byłem zadowolony z tego komponentu architektury, a opóźnienia i obciążenie serwera API były bardzo niskie. W przyszłości, jeśli to możliwe, chciałbym budować architekturę w ten sposób.