Przedstawiamy Randflake ID: rozproszony, jednolity, nieprzewidywalny, unikalny generator losowych identyfikatorów.
Rozważmy sytuację, w której musimy wygenerować unikalne 64-bitowe liczby losowe, a strony zewnętrzne nie powinny być w stanie przewidzieć następnej ani poprzedniej liczby.
W tym przypadku możemy wygenerować 8-bajtową wartość losową, sprawdzić, czy już istnieje w bazie danych, a następnie zapisać ją, jeśli jest unikalna.
Jednakże metoda ta ma kilka wad. Musimy przechowywać każdą wygenerowaną liczbę w bazie danych, aby zapewnić jej unikalność. Wymóg co najmniej jednej podróży do bazy danych powoduje problemy z opóźnieniami, szczególnie w środowisku rozproszonym, gdzie skalowalność jest kluczowa.
Aby rozwiązać te problemy, wprowadzamy Randflake ID: rozproszony, jednolity, nieprzewidywalny, unikalny generator losowych identyfikatorów.
Jak działa Randflake ID?
Randflake ID jest inspirowany Snowflake ID, szeroko stosowanym mechanizmem generowania identyfikatorów sortowanych według klucza, opracowanym przez X (dawniej Twitter).
Snowflake ID wykorzystuje bieżący znacznik czasu, ID węzła i lokalny licznik do generowania identyfikatora.
Rozszerzyliśmy to podejście do generowania losowych unikalnych identyfikatorów i dodaliśmy nowy element tajnego klucza.
Kluczową ideą jest dodanie warstwy szyfru blokowego do istniejącego generatora unikalnych identyfikatorów, aby osiągnąć niewykonalność w przewidywaniu związku między liczbami.
Szyfr blokowy to fundamentalna funkcja kryptograficzna, która przekształca blok tekstu jawnego o stałej długości w blok tekstu zaszyfrowanego o tej samej długości. Transformacja ta jest sterowana kluczem kryptograficznym. Cechą wyróżniającą szyfr blokowy jest jego odwracalność: musi to być funkcja jeden-do-jeden (bijektywna), zapewniająca, że każde unikalne wejście odpowiada unikalnemu wyjściu i odwrotnie. Ta właściwość jest kluczowa dla deszyfrowania, umożliwiając odzyskanie oryginalnego tekstu jawnego z tekstu zaszyfrowanego po zastosowaniu prawidłowego klucza.
Poprzez zastosowanie szyfru blokowego jako funkcji jeden-do-jeden, możemy zagwarantować, że każde unikalne wejście generuje odpowiadające mu unikalne wyjście w zdefiniowanym zakresie.
Struktura i uwagi projektowe
Opierając się na tych fundamentalnych koncepcjach, przeanalizujmy, w jaki sposób Randflake ID implementuje te idee w praktyce.
Struktura Randflake ID obejmuje 30-bitowy znacznik czasu unix z sekundową precyzją, 17-bitowy identyfikator węzła, 17-bitowy lokalny licznik i 64-bitowy szyfr blokowy oparty na algorytmie sparx64.
Oto kilka decyzji projektowych:
Niektóre instancje VM w Google Cloud Platform mogą synchronizować zegar z precyzją 0,2 ms, ale ten poziom dokładności nie jest dostępny w publicznym internecie ani u innych dostawców chmury.
Wybraliśmy precyzję sekundową, ponieważ możemy efektywnie synchronizować zegar między węzłami tylko z rozdzielczością kilku milisekund.
17-bitowy identyfikator węzła pozwala na 131072 indywidualnych generatorów w tym samym momencie, które mogą być przypisane na proces, na rdzeń, na wątek.
W systemach o wysokiej przepustowości 17-bitowy lokalny licznik może być niewystarczający. Aby dopasować przepustowość, możemy przypisać wiele generatorów, każdy z odrębnym ID węzła, do pracy w jednym procesie lub wątku.
Przyjęliśmy sparx64 jako 64-bitowy szyfr blokowy, nowoczesny, lekki szyfr blokowy oparty na ARX.
Randflake ID oferują wewnętrzną identyfikowalność, ujawniając swój początkowy ID węzła i znacznik czasu tylko tym, którzy posiadają tajny klucz.
Teoretyczna maksymalna przepustowość wynosi 17 179 869 184 ID/s, co jest wystarczające dla większości aplikacji o globalnej skali.
Pseudokod generowania Randflake ID
Aby dokładniej zilustrować proces generowania Randflake ID, poniższy pseudokod w Pythonie przedstawia uproszczoną implementację:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Sunday, October 27, 2024 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bitów dla znacznika czasu (żywotność 34 lata)
10RANDFLAKE_NODE_BITS = 17 # 17 bitów dla ID węzła (maksymalnie 131072 węzły)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bitów dla sekwencji (maksymalnie 131072 sekwencje)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Gotowa do produkcji implementacja Randflake, zawierająca mechanizm dzierżawy ID węzła, jest dostępna na GitHubie.
Inne rozważania
W tej sekcji omówimy kilka dodatkowych kwestii dotyczących implementacji Randflake ID.
Koordynacja ID węzła
Sugerujemy koordynację ID węzła opartą na dzierżawie.
W tym podejściu centralna usługa koordynacyjna przypisuje unikalny ID węzła każdemu generatorowi.
Ten ID węzła nie jest ponownie przypisywany w okresie dzierżawy, aby zapewnić unikalność, zmniejszając potrzebę częstej komunikacji z usługą koordynacyjną.
Generator posiadający dzierżawę może zażądać odnowienia dzierżawy od usługi koordynacyjnej, jeśli spełnione są warunki odnowienia.
Warunek odnowienia odnosi się do zestawu kryteriów, które muszą być spełnione, aby dzierżawa została odnowiona, takich jak aktywność generatora i zapotrzebowanie na ID węzła.
Dzierżawca jest obecnym posiadaczem zakresu ID węzła.
Dzierżawa jest uważana za aktywną i nie wygasłą, jeśli mieści się w swoim ważnym okresie czasu.
W ten sposób możemy zredukować liczbę podróży do jednej na okres odnowienia dzierżawy, minimalizując opóźnienia i poprawiając wydajność w systemach rozproszonych.
Łagodzenie skutków wadliwego zegara
Usługa dzierżawy musi sprawdzać spójność znacznika czasu podczas przydzielania dzierżawy. Przypisany czas rozpoczęcia dzierżawy musi być większy lub równy czasowi rozpoczęcia ostatniej dzierżawy.
Generator powinien odrzucić żądanie, jeśli bieżący znacznik czasu jest mniejszy niż czas rozpoczęcia dzierżawy lub większy niż czas zakończenia dzierżawy.
Procedura ta jest ważna w celu ochrony unikalności generowanych identyfikatorów, gdy zegar cofa się. Na przykład, jeśli zegar cofa się, nowa dzierżawa może zostać przypisana z czasem rozpoczęcia wcześniejszym niż wcześniej przypisana dzierżawa, co potencjalnie prowadzi do generowania zduplikowanych identyfikatorów. Poprzez odrzucanie żądań ze znacznikami czasu w istniejącym okresie dzierżawy zapobiegamy temu scenariuszowi i utrzymujemy unikalność identyfikatorów.
Jednolitość rozkładu identyfikatorów
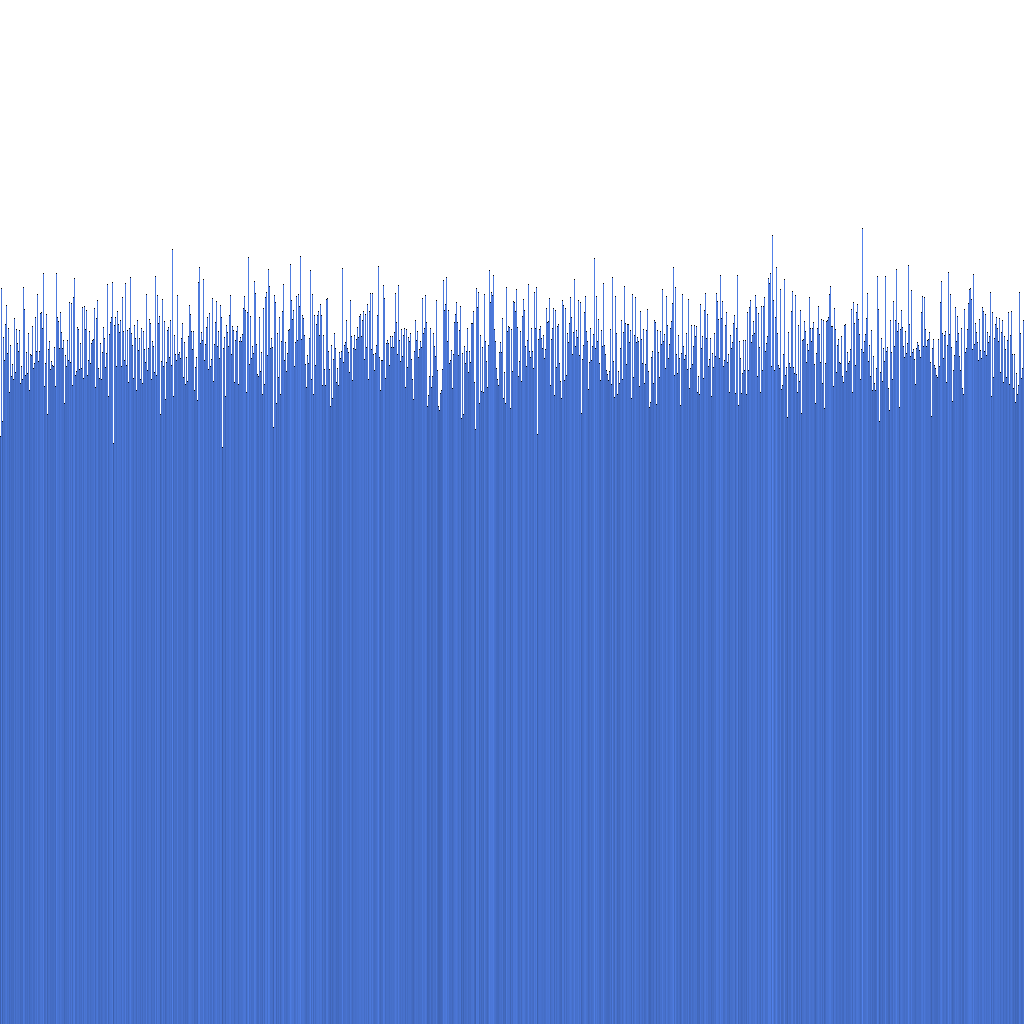
Na podstawie powyższego histogramu widać, że rozkład generowanych Randflake ID jest bardzo jednolity. Sugeruje to, że rozkład ID może być bezpośrednio użyty jako klucz shardingowy.
Wnioski
W tym artykule przedstawiliśmy Randflake, nowy algorytm generowania identyfikatorów, który łączy zalety Snowflake i Sparx64.
Mamy nadzieję, że ten artykuł zapewnił Państwu kompleksowe zrozumienie Randflake i jego implementacji.
Pełny kod źródłowy Randflake można znaleźć na GitHubie.
W przypadku pytań lub sugestii prosimy o kontakt. Poszukujemy również współpracowników, którzy pomogą ulepszyć Randflake i zaimplementować go w innych językach programowania.
Planujemy wydać gotową do produkcji usługę koordynacji dla Randflake i Snowflake, która zostanie udostępniona jako open-source na GitHubie. Bądźcie Państwo na bieżąco!