Aprimorando a Reatividade com o Cache do Lado do Cliente do Redis
O que é Redis?
Acredito que poucas pessoas não conheçam o Redis. No entanto, para aqueles que não o conhecem, posso resumi-lo brevemente com algumas de suas características:
- As operações são executadas em um único thread, o que confere atomicidade a todas as operações.
- Os dados são armazenados e processados In-Memory, tornando todas as operações rápidas.
- O Redis pode armazenar WAL (Write-Ahead Log), dependendo das opções, permitindo backup e recuperação rápidos do estado mais recente.
- Suporta vários tipos de dados, como Set, Hash, Bit, List, oferecendo alta produtividade.
- Possui uma grande comunidade, permitindo compartilhar diversas experiências, problemas e soluções.
- Tem sido desenvolvido e operado por um longo tempo, conferindo-lhe estabilidade confiável.
Ao ponto principal
Imagine?
E se o cache do seu serviço atendesse às duas seguintes condições?
- É preciso fornecer dados frequentemente consultados aos usuários no estado mais recente, mas a atualização é irregular, exigindo atualizações frequentes do cache.
- A atualização não ocorre, mas é preciso acessar e consultar os mesmos dados em cache com frequência.
O primeiro caso pode considerar o ranking de popularidade em tempo real de um shopping online. Quando o ranking de popularidade em tempo real é armazenado como um sorted set, ler do Redis toda vez que um usuário acessa a página principal é ineficiente. No segundo caso, para dados de câmbio, mesmo que os dados sejam divulgados aproximadamente a cada 10 minutos, as consultas reais ocorrem com muita frequência. Além disso, o cache é consultado com muita frequência para as taxas de câmbio de won-dólar, won-iene e won-yuan. Nesses casos, seria mais eficiente que o servidor da API mantivesse um cache separado localmente e, quando os dados fossem alterados, consultasse o Redis novamente para atualizá-lo.
Então, como podemos implementar esse comportamento em uma arquitetura de banco de dados - Redis - servidor de API?
Redis PubSub não funcionaria?
Ao usar o cache, vamos nos inscrever em um canal que pode receber notificações de atualização!
- Então, precisamos criar uma lógica para enviar mensagens no momento da atualização.
- A operação adicional devido ao PubSub afeta o desempenho.
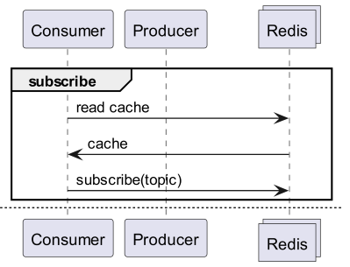
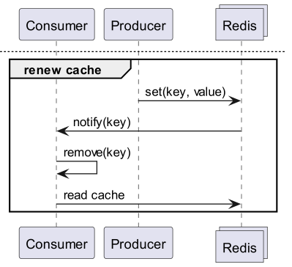
E se o Redis detectasse as mudanças?
E se usássemos Keyspace Notification para receber notificações de comandos para uma chave específica?
- Existe a inconveniência de ter que armazenar e compartilhar antecipadamente as chaves e comandos usados para a atualização.
- Por exemplo, para algumas chaves, um simples
Seté o comando de atualização, enquanto para outras,LPush,RPush,SAddouSRemsão os comandos de atualização, tornando-se complexo. - Isso aumenta consideravelmente a possibilidade de falhas de comunicação e erros humanos na codificação durante o processo de desenvolvimento.
E se usássemos Keyevent Notification para receber notificações por comando?
- É necessário inscrever-se em todos os comandos usados para atualização. É preciso uma filtragem adequada para as chaves recebidas.
- Por exemplo, para algumas das chaves que chegam via
Del, é provável que o cliente correspondente não tenha um cache local. - Isso pode levar ao desperdício desnecessário de recursos.
Portanto, o que é necessário é a Invalidation Message!
O que é Invalidation Message?
Invalidation Messages é um conceito fornecido como parte do Server Assisted Client-Side Cache, adicionado a partir do Redis 6.0. A Invalidation Message é transmitida no seguinte fluxo:
- Assume-se que o ClientB já leu a chave uma vez.
- O ClientA define um novo valor para essa chave.
- O Redis detecta a mudança e publica uma Invalidation Message para o ClientB, notificando-o para limpar o cache.
- O ClientB recebe essa mensagem e toma as medidas apropriadas.
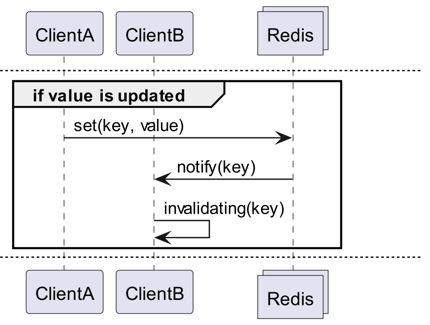
Como usar
Estrutura de Operação Básica
Um cliente conectado ao Redis executa CLIENT TRACKING ON REDIRECT <client-id> para receber mensagens de invalidação. Em seguida, o cliente que precisa receber as mensagens se inscreve em SUBSCRIBE __redis__:invalidate para recebê-las.
default tracking
1# client 1
2> SET a 100
1# client 3
2> CLIENT ID
312
4> SUBSCRIBE __redis__:invalidate
51) "subscribe"
62) "__redis__:invalidate"
73) (integer) 1
1# client 2
2> CLIENT TRACKING ON REDIRECT 12
3> GET a # tracking
1# client 1
2> SET a 200
1# client 3
21) "message"
32) "__redis__:invalidate"
43) 1) "a"
broadcasting tracking
1# client 3
2> CLIENT ID
312
4> SUBSCRIBE __redis__:invalidate
51) "subscribe"
62) "__redis__:invalidate"
73) (integer) 1
1# client 2
2CLIENT TRACKING ON BCAST PREFIX cache: REDIRECT 12
1# client 1
2> SET cache:name "Alice"
3> SET cache:age 26
1# client 3
21) "message"
32) "__redis__:invalidate"
43) 1) "cache:name"
51) "message"
62) "__redis__:invalidate"
73) 1) "cache:age"
Implementação! Implementação! Implementação!
Redigo + Ristretto
A explicação acima pode ser ambígua sobre como usar na prática no código. Então, vamos configurar isso simplesmente com redigo e ristretto primeiro.
Primeiro, instale as duas dependências.
github.com/gomodule/redigogithub.com/dgraph-io/ristretto
1package main
2
3import (
4 "context"
5 "fmt"
6 "log/slog"
7 "time"
8
9 "github.com/dgraph-io/ristretto"
10 "github.com/gomodule/redigo/redis"
11)
12
13type RedisClient struct {
14 conn redis.Conn
15 cache *ristretto.Cache[string, any]
16 addr string
17}
18
19func NewRedisClient(addr string) (*RedisClient, error) {
20 cache, err := ristretto.NewCache(&ristretto.Config[string, any]{
21 NumCounters: 1e7, // número de chaves para rastrear a frequência (10M).
22 MaxCost: 1 << 30, // custo máximo do cache (1GB).
23 BufferItems: 64, // número de chaves por buffer Get.
24 })
25 if err != nil {
26 return nil, fmt.Errorf("failed to generate cache: %w", err)
27 }
28
29 conn, err := redis.Dial("tcp", addr)
30 if err != nil {
31 return nil, fmt.Errorf("failed to connect to redis: %w", err)
32 }
33
34 return &RedisClient{
35 conn: conn,
36 cache: cache,
37 addr: addr,
38 }, nil
39}
40
41func (r *RedisClient) Close() error {
42 err := r.conn.Close()
43 if err != nil {
44 return fmt.Errorf("failed to close redis connection: %w", err)
45 }
46
47 return nil
48}
Primeiro, criamos um RedisClient que inclui ristretto e redigo de forma simples.
1func (r *RedisClient) Tracking(ctx context.Context) error {
2 psc, err := redis.Dial("tcp", r.addr)
3 if err != nil {
4 return fmt.Errorf("failed to connect to redis: %w", err)
5 }
6
7 clientId, err := redis.Int64(psc.Do("CLIENT", "ID"))
8 if err != nil {
9 return fmt.Errorf("failed to get client id: %w", err)
10 }
11 slog.Info("client id", "id", clientId)
12
13 subscriptionResult, err := redis.String(r.conn.Do("CLIENT", "TRACKING", "ON", "REDIRECT", clientId))
14 if err != nil {
15 return fmt.Errorf("failed to enable tracking: %w", err)
16 }
17 slog.Info("subscription result", "result", subscriptionResult)
18
19 if err := psc.Send("SUBSCRIBE", "__redis__:invalidate"); err != nil {
20 return fmt.Errorf("failed to subscribe: %w", err)
21 }
22 psc.Flush()
23
24 for {
25 msg, err := psc.Receive()
26 if err != nil {
27 return fmt.Errorf("failed to receive message: %w", err)
28 }
29
30 switch msg := msg.(type) {
31 case redis.Message:
32 slog.Info("received message", "channel", msg.Channel, "data", msg.Data)
33 key := string(msg.Data)
34 r.cache.Del(key)
35 case redis.Subscription:
36 slog.Info("subscription", "kind", msg.Kind, "channel", msg.Channel, "count", msg.Count)
37 case error:
38 return fmt.Errorf("error: %w", msg)
39 case []interface{}:
40 if len(msg) != 3 || string(msg[0].([]byte)) != "message" || string(msg[1].([]byte)) != "__redis__:invalidate" {
41 slog.Warn("unexpected message", "message", msg)
42 continue
43 }
44
45 contents := msg[2].([]interface{})
46 keys := make([]string, len(contents))
47 for i, key := range contents {
48 keys[i] = string(key.([]byte))
49 r.cache.Del(keys[i])
50 }
51 slog.Info("received invalidation message", "keys", keys)
52 default:
53 slog.Warn("unexpected message", "type", fmt.Sprintf("%T", msg))
54 }
55 }
56}
O código é um pouco complexo.
- Para realizar o Tracking, é estabelecida uma conexão adicional. Esta medida visa evitar que o PubSub interfira em outras operações.
- O ID da conexão adicional é consultado e a conexão que consulta os dados é redirecionada para essa conexão para o Tracking.
- Em seguida, as mensagens de invalidação são subscritas.
- O código que lida com a subscrição é um pouco complexo. Como o redigo não faz a análise das mensagens de invalidação, é necessário receber e processar a resposta antes da análise.
1func (r *RedisClient) Get(key string) (any, error) {
2 val, found := r.cache.Get(key)
3 if found {
4 switch v := val.(type) {
5 case int64:
6 slog.Info("cache hit", "key", key)
7 return v, nil
8 default:
9 slog.Warn("unexpected type", "type", fmt.Sprintf("%T", v))
10 }
11 }
12 slog.Info("cache miss", "key", key)
13
14 val, err := redis.Int64(r.conn.Do("GET", key))
15 if err != nil {
16 return nil, fmt.Errorf("failed to get key: %w", err)
17 }
18
19 r.cache.SetWithTTL(key, val, 1, 10*time.Second)
20 return val, nil
21}
A mensagem Get primeiro consulta o ristretto e, se não encontrar, busca no Redis, conforme mostrado acima.
1package main
2
3import (
4 "context"
5 "log/slog"
6 "os"
7 "os/signal"
8 "time"
9)
10
11func main() {
12 ctx, cancel := signal.NotifyContext(context.Background(), os.Interrupt)
13 defer cancel()
14
15 client, err := NewRedisClient("localhost:6379")
16 if err != nil {
17 panic(err)
18 }
19 defer client.Close()
20
21 go func() {
22 if err := client.Tracking(ctx); err != nil {
23 slog.Error("failed to track invalidation message", "error", err)
24 }
25 }()
26
27 ticker := time.NewTicker(1 * time.Second)
28 defer ticker.Stop()
29 done := ctx.Done()
30
31 for {
32 select {
33 case <-done:
34 slog.Info("shutting down")
35 return
36 case <-ticker.C:
37 v, err := client.Get("key")
38 if err != nil {
39 slog.Error("failed to get key", "error", err)
40 return
41 }
42 slog.Info("got key", "value", v)
43 }
44 }
45}
O código para teste é o acima. Se você testar, poderá ver que o valor é atualizado sempre que os dados no Redis são atualizados.
No entanto, isso é muito complexo. Acima de tudo, para escalar para um cluster, é inevitável ativar o Tracking para todos os masters ou réplicas.
Rueidis
Para quem usa Go, temos o rueidis, que é o mais moderno e avançado. Vamos escrever um código que utiliza o cache do lado do cliente assistido pelo servidor no ambiente de cluster Redis, usando o rueidis.
Primeiro, instale a dependência.
github.com/redis/rueidis
E então escreva o código para consultar dados no Redis.
1package main
2
3import (
4 "context"
5 "log/slog"
6 "os"
7 "os/signal"
8 "time"
9
10 "github.com/redis/rueidis"
11)
12
13func main() {
14 ctx, cancel := signal.NotifyContext(context.Background(), os.Interrupt)
15 defer cancel()
16
17 client, err := rueidis.NewClient(rueidis.ClientOption{
18 InitAddress: []string{"localhost:6379"},
19 })
20 if err != nil {
21 panic(err)
22 }
23
24 ticker := time.NewTicker(1 * time.Second)
25 defer ticker.Stop()
26 done := ctx.Done()
27
28 for {
29 select {
30 case <-done:
31 slog.Info("shutting down")
32 return
33 case <-ticker.C:
34 const key = "key"
35 resp := client.DoCache(ctx, client.B().Get().Key(key).Cache(), 10*time.Second)
36 if resp.Error() != nil {
37 slog.Error("failed to get key", "error", resp.Error())
38 continue
39 }
40 i, err := resp.AsInt64()
41 if err != nil {
42 slog.Error("failed to convert response to int64", "error", err)
43 continue
44 }
45 switch resp.IsCacheHit() {
46 case true:
47 slog.Info("cache hit", "key", key)
48 case false:
49 slog.Info("missed key", "key", key)
50 }
51 slog.Info("got key", "value", i)
52 }
53 }
54}
No rueidis, para usar o client side cache, basta usar DoCache. Isso adiciona os dados ao cache local, incluindo por quanto tempo devem ser mantidos, e uma chamada subsequente a DoCache recupera os dados do cache local. Naturalmente, as mensagens de invalidação também são tratadas corretamente.
Por que não redis-go?
O redis-go infelizmente não oferece suporte oficial para o server assisted client side cache através de sua API. Além disso, ao criar um PubSub, ele não possui uma API para acessar diretamente a conexão recém-criada, o que impossibilita a obtenção do client id. Por isso, considerei que a configuração com redis-go seria inviável e o descartei.
Que interessante
Através da estrutura do client side cache
- Se os dados puderem ser preparados com antecedência, essa estrutura pode minimizar as consultas e o tráfego para o Redis, fornecendo sempre os dados mais recentes.
- Isso permite criar uma espécie de estrutura CQRS, aumentando drasticamente o desempenho de leitura.

O quão mais interessante ficou?
Na prática, como essa estrutura já está sendo usada, analisei a latência de duas APIs. Peço desculpas por não poder fornecer detalhes mais específicos.
- Primeira API
- Consulta inicial: média de 14.63ms
- Consultas subsequentes: média de 2.82ms
- Diferença média: 10.98ms
- Segunda API
- Consulta inicial: média de 14.05ms
- Consultas subsequentes: média de 1.60ms
- Diferença média: 11.57ms
Houve uma melhoria adicional na latência de até 82%!
Espera-se que as seguintes melhorias tenham ocorrido:
- Eliminação da comunicação de rede entre o cliente e o Redis e economia de tráfego.
- Redução do número de comandos de leitura que o próprio Redis precisa executar.
- Isso também tem o efeito de aumentar o desempenho de escrita.
- Minimização da análise do protocolo Redis.
- A análise do protocolo Redis não é gratuita. Reduzir isso é uma grande oportunidade.
No entanto, tudo é uma troca. Para isso, sacrificamos pelo menos os dois pontos a seguir:
- Necessidade de implementar, operar e manter um componente de gerenciamento de cache do lado do cliente.
- Aumento do uso de CPU e memória do cliente resultante.
Conclusão
Pessoalmente, foi um componente de arquitetura satisfatório, e a latência e o estresse no servidor da API foram muito baixos. Continuarei a considerar a construção de arquiteturas com essa estrutura sempre que possível.