Apresentando Randflake ID: um gerador de ID aleatório distribuído, uniforme, imprevisível e único.
Considere uma situação em que precisamos gerar números aleatórios únicos de 64 bits, e partes externas não devem ser capazes de prever o número seguinte ou anterior.
Aqui, podemos gerar um valor aleatório de 8 bytes, verificar se ele já existe no banco de dados e, em seguida, armazená-lo se for único.
No entanto, este método apresenta diversas desvantagens. Temos que armazenar cada número gerado em um banco de dados para garantir a unicidade. A exigência de pelo menos uma ida e volta ao banco de dados cria problemas de latência, particularmente em um ambiente distribuído onde a escalabilidade é crucial.
Para resolver esses problemas, estamos introduzindo o Randflake ID: um gerador de ID aleatório distribuído, uniforme, imprevisível e único.
Como o Randflake ID funciona?
O Randflake ID é inspirado no Snowflake ID, o mecanismo de geração de ID k-ordenado amplamente utilizado e desenvolvido pela X (anteriormente Twitter).
O Snowflake ID utiliza o timestamp atual, um ID de nó e um contador local para gerar um identificador.
Expandimos ainda mais essa abordagem para a geração de ID único aleatório e adicionamos um novo elemento de chave secreta.
A ideia chave é adicionar uma camada de cifra de bloco ao gerador de ID único existente para tornar inviável a previsão da relação entre os números.
Uma cifra de bloco é uma função criptográfica fundamental que transforma um bloco de texto simples de comprimento fixo em um bloco de texto cifrado do mesmo comprimento. Essa transformação é governada por uma chave criptográfica. A característica distintiva de uma cifra de bloco é sua reversibilidade: ela deve ser uma função um-para-um (bijetora), garantindo que cada entrada única corresponda a uma saída única, e vice-versa. Essa propriedade é crucial para a descriptografia, permitindo que o texto simples original seja recuperado do texto cifrado quando a chave correta é aplicada.
Ao empregar uma cifra de bloco como uma função um-para-um, podemos garantir que cada entrada única produza uma saída única correspondente dentro do intervalo definido.
A estrutura e considerações de design
Com base nesses conceitos fundamentais, vamos examinar como o Randflake ID implementa essas ideias na prática.
A estrutura do Randflake ID inclui um timestamp unix de 30 bits com precisão de segundo, um identificador de nó de 17 bits, um contador local de 17 bits e uma cifra de bloco de 64 bits baseada no algoritmo sparx64.
Aqui estão algumas decisões de design:
Algumas instâncias de VM na Google Cloud Platform podem sincronizar o relógio com precisão de 0,2ms, mas esse nível de precisão não está disponível na internet pública ou em outros provedores de nuvem.
Selecionamos a precisão de segundo porque podemos sincronizar efetivamente o relógio entre os nós apenas com resoluções de poucos milissegundos.
O identificador de nó de 17 bits permite 131072 geradores individuais no mesmo momento, que podem ser atribuídos por processo, por núcleo, por thread.
Em sistemas de alta taxa de transferência, o contador local de 17 bits pode ser insuficiente. Para corresponder à taxa de transferência, podemos atribuir múltiplos geradores, cada um com um ID de nó distinto, para trabalhar em um único processo ou thread.
Adotamos o sparx64 como uma cifra de bloco de 64 bits, uma cifra de bloco ARX-based moderna e leve.
Os Randflake IDs oferecem rastreabilidade interna, revelando seu ID de nó de origem e timestamp apenas para aqueles que possuem a chave secreta.
A taxa de transferência máxima teórica é de 17.179.869.184 ID/s, o que é suficiente para a maioria das aplicações em escala global.
Pseudocódigo da geração de Randflake ID
Para ilustrar ainda mais o processo de geração do Randflake ID, o seguinte pseudocódigo Python fornece uma implementação simplificada:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Domingo, 27 de outubro de 2024 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bits para timestamp (vida útil de 34 anos)
10RANDFLAKE_NODE_BITS = 17 # 17 bits para id do nó (máximo de 131072 nós)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bits para sequência (máximo de 131072 sequências)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Uma implementação do Randflake pronta para produção, apresentando um mecanismo de lease de ID de nó, está disponível no GitHub.
Outras considerações
Nesta seção, discutiremos algumas considerações adicionais para a implementação do Randflake ID.
Coordenação de Node ID
Sugerimos a coordenação de ID de nó baseada em lease.
Nesta abordagem, um serviço de coordenação central atribui um ID de nó único a cada gerador.
Este ID de nó não é reatribuído durante o período de lease para garantir a unicidade, reduzindo a necessidade de comunicação frequente com o serviço de coordenação.
O gerador que detém o lease pode solicitar uma renovação do lease ao serviço de coordenação se a condição de renovação for atendida.
A condição de renovação refere-se a um conjunto de critérios que devem ser satisfeitos para que o lease seja renovado, como o gerador ainda estar ativo e necessitar do ID do nó.
O detentor do lease é o atual possuidor do intervalo de ID de nó.
O lease é considerado ativo e não expirado se estiver dentro de seu período de validade.
Dessa forma, podemos reduzir as idas e vindas para uma por período de renovação de lease, minimizando a latência e melhorando a eficiência em sistemas distribuídos.
Mitigação contra relógio defeituoso
O serviço de lease deve verificar a consistência do timestamp ao alocar um lease. O tempo de início do lease atribuído deve ser maior ou igual ao tempo de início do último lease.
O gerador deve rejeitar a solicitação se o timestamp atual for menor que o tempo de início do lease ou maior que o tempo de término do lease.
Este procedimento é importante para proteger a unicidade dos IDs gerados quando o relógio retrocede. Por exemplo, se um relógio retrocede, um novo lease poderia ser atribuído com um tempo de início anterior a um lease previamente atribuído, potencialmente levando à geração de IDs duplicados. Ao rejeitar solicitações com timestamps dentro de um período de lease existente, prevenimos esse cenário e mantemos a unicidade dos IDs.
Uniformidade da distribuição de ID
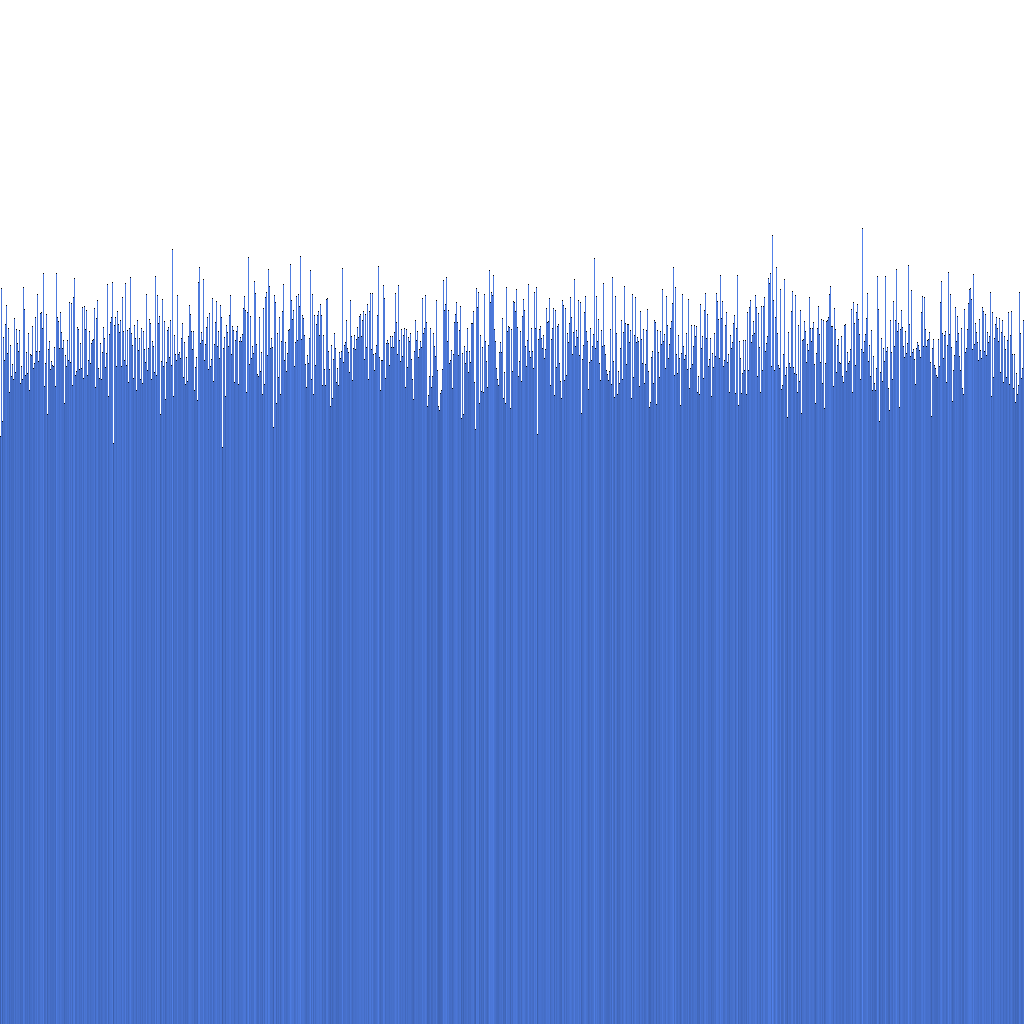
Com base no histograma acima, podemos observar que a distribuição dos Randflake IDs gerados é muito uniforme. Isso sugere que a distribuição de ID pode ser utilizada diretamente como uma chave de sharding.
Conclusão
Neste artigo, apresentamos o Randflake, um novo algoritmo de geração de ID que combina as vantagens do Snowflake e do Sparx64.
Esperamos que este artigo tenha fornecido uma compreensão abrangente do Randflake e de sua implementação.
Você pode encontrar o código-fonte completo do Randflake no GitHub.
Se tiver alguma dúvida ou sugestão, não hesite em nos contatar. Também estamos procurando colaboradores para ajudar a aprimorar o Randflake e implementá-lo em outras linguagens de programação.
Estamos planejando lançar um serviço de coordenação pronto para produção para Randflake e Snowflake, que será de código aberto no GitHub. Fique atento às atualizações!