Introducing Randflake ID: a distributed, uniform, unpredictable, unique random ID generator.
Consider a situation where we need to generate unique 64-bit random numbers, and external parties should not be able to predict the next or previous number.
Here, we can generate an 8-byte random value, check if it already exists in the database, and then store it if it is unique.
However, this method has several drawbacks. We have to store every number generated in a database to ensure uniqueness. The requirement for at least one round trip to the database creates latency issues, particularly in a distributed environment where scalability is crucial.
To solve these problems, we are introducing Randflake ID: a distributed, uniform, unpredictable, unique random ID generator.
How Does Randflake ID Work?
Randflake ID is inspired by Snowflake ID, the widely used k-sorted id generation mechanism developed by X (formerly twitter).
Snowflake ID uses the current timestamp, a node ID, and a local counter to generate an identifier.
We expanded this approach further for random unique ID generation and added a new secret key element.
The key idea is adding a block cipher layer to the existing unique ID generator to achieve infeasibility in predicting the relationship between numbers.
A block cipher is a fundamental cryptographic function that transforms a fixed-length block of plaintext into a block of ciphertext of the same length. This transformation is governed by a cryptographic key. The distinguishing characteristic of a block cipher is its reversibility: it must be a one-to-one (bijective) function, ensuring that each unique input corresponds to a unique output, and vice versa. This property is crucial for decryption, allowing the original plaintext to be recovered from the ciphertext when the correct key is applied.
By employing a block cipher as a one-to-one function, we can guarantee that each unique input produces a corresponding unique output within the defined range.
The structure and design consideration
Building upon these fundamental concepts, let's examine how Randflake ID implements these ideas in practice.
The Randflake ID structure includes a 30-bit unix timestamp at second precision, a 17-bit node identifier, a 17-bit local counter, and a 64-bit block cipher based on the sparx64 algorithm.
Here are some design decisions:
Some VM instances in Google Cloud Platform can synchronize the clock within 0.2ms precision, but that level of accuracy is not available on public internet or other cloud provider.
We selected a second precision because we can effectively synchronize the clock between nodes only within a few millisecond resolutions.
17-bit node identifier allows 131072 individual generators at the same moment, which can be assigned per-process, per-core, per-thread manner.
In high throughput systems, 17-bit local counter may be insufficient. To match the throughput, we can assign multiple generators, each with a distinct node ID, to work in a single process or thread.
We adopted sparx64 as a 64-bit block cipher, a modern lightweight ARX-based block cipher.
Randflake IDs offer internal traceability, revealing their originating node ID and timestamp only to those who possess the secret key.
Theoretical maximum throughput is 17,179,869,184 ID/s, which is sufficient for most global scale application.
Pseudocode of Randflake ID generation
To further illustrate the Randflake ID generation process, the following Python pseudocode provides a simplified implementation:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Sunday, October 27, 2024 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bits for timestamp (lifetime of 34 years)
10RANDFLAKE_NODE_BITS = 17 # 17 bits for node id (max 131072 nodes)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bits for sequence (max 131072 sequences)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
A production-ready implementation of Randflake, featuring a node ID lease mechanism, is available on GitHub.
Other considerations
In this section, we will discuss some additional considerations for implementing Randflake ID.
Node ID coordination
We suggest lease-based node ID coordination.
In this approach, a central coordination service assigns a unique node ID to each generator.
This node ID is not reassigned during the lease period to ensure uniqueness, reducing the need for frequent communication with the coordination service.
The generator holding the lease can request a renewal of the lease from the coordination service if the renewal condition is met.
The renewal condition refers to a set of criteria that must be satisfied for the lease to be renewed, such as the generator still being active and requiring the node ID.
The leaseholder is the current holder of the node ID range.
The lease is considered active and not expired if it is within its valid time period.
This way, we can reduce round trips to one per lease renewal period, minimizing latency and improving efficiency in distributed systems.
Mitigation against faulty clock
The lease service must check timestamp consistency when allocating a lease. The assigned lease start time must be greater than or equal to the last lease start time.
The generator should reject the request if the current timestamp is less than the lease start time or greater than the lease end time.
This procedure is important to protect the uniqueness of generated IDs when the clock jumps backward. For instance, if a clock jumps backward, a new lease could be assigned with a start time earlier than a previously assigned lease, potentially leading to duplicate IDs being generated. By rejecting requests with timestamps within an existing lease period, we prevent this scenario and maintain the uniqueness of the IDs.
Uniformity of ID distribution
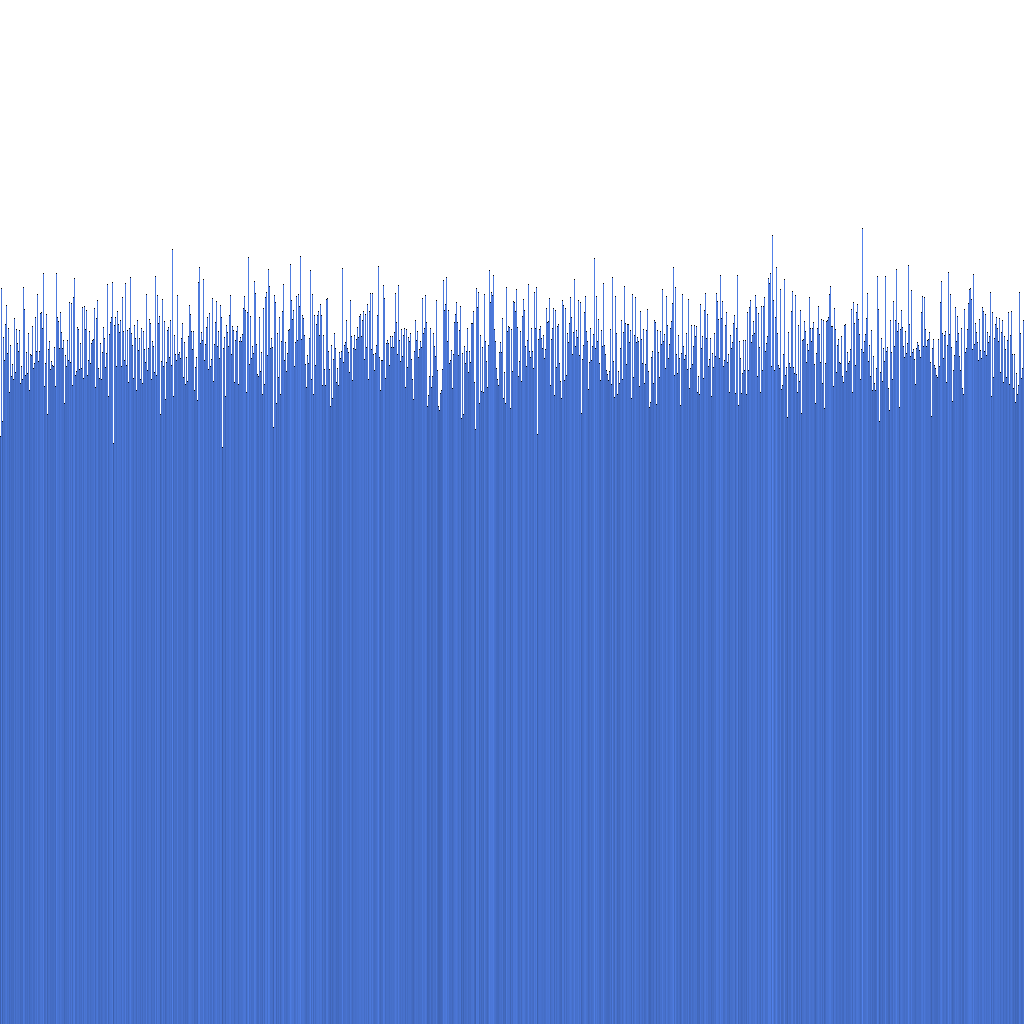
Based on the histogram above, we can see that the distribution of generated Randflake IDs is very uniform. This suggests that the ID distribution can be used directly as a sharding key.
Conclusion
In this article, we introduced Randflake, a novel ID generation algorithm that combines the advantages of Snowflake and Sparx64.
We hope this article has provided you with a comprehensive understanding of Randflake and its implementation.
You can find the full source code for Randflake on GitHub.
If you have any questions or suggestions, please don't hesitate to reach out. We're also looking for contributors to help improve Randflake and implement it in other programming languages.
We are planning to release a production-ready coordination service for Randflake and Snowflake, which will be open-sourced on GitHub. Stay tuned for updates!