Vă prezentăm Randflake ID: un generator de ID-uri aleatoare distribuit, uniform, impredictibil și unic.
Considerați o situație în care trebuie să generăm numere aleatoare unice pe 64 de biți, iar părțile externe nu ar trebui să poată prezice numărul următor sau anterior.
Aici, putem genera o valoare aleatoare de 8 octeți, să verificăm dacă există deja în baza de date și apoi să o stocăm dacă este unică.
Cu toate acestea, această metodă prezintă mai multe dezavantaje. Trebuie să stocăm fiecare număr generat într-o bază de date pentru a asigura unicitatea. Necesitatea a cel puțin unei călătorii dus-întors către baza de date creează probleme de latență, în special într-un mediu distribuit unde scalabilitatea este crucială.
Pentru a rezolva aceste probleme, introducem Randflake ID: un generator de ID-uri aleatoare distribuit, uniform, impredictibil și unic.
Cum funcționează Randflake ID?
Randflake ID este inspirat de Snowflake ID, mecanismul de generare a ID-urilor sortate k, utilizat pe scară largă, dezvoltat de X (fostul Twitter).
Snowflake ID utilizează timestamp-ul curent, un ID de nod și un contor local pentru a genera un identificator.
Am extins această abordare pentru generarea de ID-uri unice aleatoare și am adăugat un nou element de cheie secretă.
Ideea cheie este adăugarea unui strat de cifrare pe bloc la generatorul de ID-uri unice existent pentru a realiza imposibilitatea de a prezice relația dintre numere.
Un cifru pe bloc este o funcție criptografică fundamentală care transformă un bloc de text clar de lungime fixă într-un bloc de text cifrat de aceeași lungime. Această transformare este guvernată de o cheie criptografică. Caracteristica distinctivă a unui cifru pe bloc este reversibilitatea sa: trebuie să fie o funcție unu-la-unu (bijectivă), asigurându-se că fiecare intrare unică corespunde unei ieșiri unice și viceversa. Această proprietate este crucială pentru decriptare, permițând recuperarea textului clar original din textul cifrat atunci când este aplicată cheia corectă.
Prin utilizarea unui cifru pe bloc ca funcție unu-la-unu, putem garanta că fiecare intrare unică produce o ieșire unică corespunzătoare în intervalul definit.
Structura și considerentele de proiectare
Bazându-ne pe aceste concepte fundamentale, să examinăm modul în care Randflake ID implementează aceste idei în practică.
Structura Randflake ID include un timestamp unix pe 30 de biți cu precizie de secundă, un identificator de nod pe 17 biți, un contor local pe 17 biți și un cifru pe bloc pe 64 de biți bazat pe algoritmul sparx64.
Iată câteva decizii de proiectare:
Unele instanțe VM în Google Cloud Platform pot sincroniza ceasul cu o precizie de 0,2 ms, dar acest nivel de precizie nu este disponibil pe internetul public sau la alți furnizori de cloud.
Am selectat o precizie de secundă deoarece putem sincroniza eficient ceasul între noduri doar cu o rezoluție de câteva milisecunde.
Identificatorul de nod pe 17 biți permite 131072 de generatoare individuale în același moment, care pot fi alocate per-proces, per-core, per-thread.
În sistemele cu debit mare, contorul local pe 17 biți poate fi insuficient. Pentru a se potrivi debitului, putem aloca mai multe generatoare, fiecare cu un ID de nod distinct, să lucreze într-un singur proces sau thread.
Am adoptat sparx64 ca un cifru pe bloc pe 64 de biți, un cifru pe bloc modern, ușor, bazat pe ARX.
ID-urile Randflake oferă trasabilitate internă, relevând ID-ul nodului de origine și timestamp-ul doar celor care dețin cheia secretă.
Debitul maxim teoretic este de 17.179.869.184 ID/s, ceea ce este suficient pentru majoritatea aplicațiilor la scară globală.
Pseudocod pentru generarea Randflake ID
Pentru a ilustra în continuare procesul de generare a Randflake ID, următorul pseudocod Python oferă o implementare simplificată:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Sunday, October 27, 2024 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 de biți pentru timestamp (durată de viață de 34 de ani)
10RANDFLAKE_NODE_BITS = 17 # 17 biți pentru ID-ul nodului (max 131072 noduri)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 biți pentru secvență (max 131072 secvențe)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
O implementare pregătită pentru producție a Randflake, incluzând un mecanism de închiriere a ID-ului de nod, este disponibilă pe GitHub.
Alte considerații
În această secțiune, vom discuta câteva considerații suplimentare pentru implementarea Randflake ID.
Coordonarea ID-ului de nod
Sugestia noastră este coordonarea ID-ului de nod bazată pe închiriere.
În această abordare, un serviciu central de coordonare atribuie un ID de nod unic fiecărui generator.
Acest ID de nod nu este realocat pe durata perioadei de închiriere pentru a asigura unicitatea, reducând necesitatea unei comunicări frecvente cu serviciul de coordonare.
Generatorul care deține închirierea poate solicita o reînnoire a închirierii de la serviciul de coordonare dacă este îndeplinită condiția de reînnoire.
Condiția de reînnoire se referă la un set de criterii care trebuie îndeplinite pentru ca închirierea să fie reînnoită, cum ar fi generatorul fiind încă activ și necesitând ID-ul de nod.
Deținătorul închirierii este actualul deținător al intervalului de ID-uri de nod.
Închirierea este considerată activă și neexpirată dacă se află în perioada sa de valabilitate.
În acest fel, putem reduce călătoriile dus-întors la una per perioadă de reînnoire a închirierii, minimizând latența și îmbunătățind eficiența în sistemele distribuite.
Atenuarea împotriva ceasului defect
Serviciul de închiriere trebuie să verifice consistența timestamp-ului la alocarea unei închirieri. Ora de începere a închirierii alocate trebuie să fie mai mare sau egală cu ultima oră de începere a închirierii.
Generatorul ar trebui să respingă cererea dacă timestamp-ul curent este mai mic decât ora de începere a închirierii sau mai mare decât ora de încheiere a închirierii.
Această procedură este importantă pentru a proteja unicitatea ID-urilor generate atunci când ceasul sare înapoi. De exemplu, dacă un ceas sare înapoi, o nouă închiriere ar putea fi atribuită cu o oră de începere anterioară unei închirieri atribuite anterior, ceea ce ar putea duce la generarea de ID-uri duplicate. Prin respingerea cererilor cu timestamp-uri în cadrul unei perioade de închiriere existente, prevenim acest scenariu și menținem unicitatea ID-urilor.
Uniformitatea distribuției ID-urilor
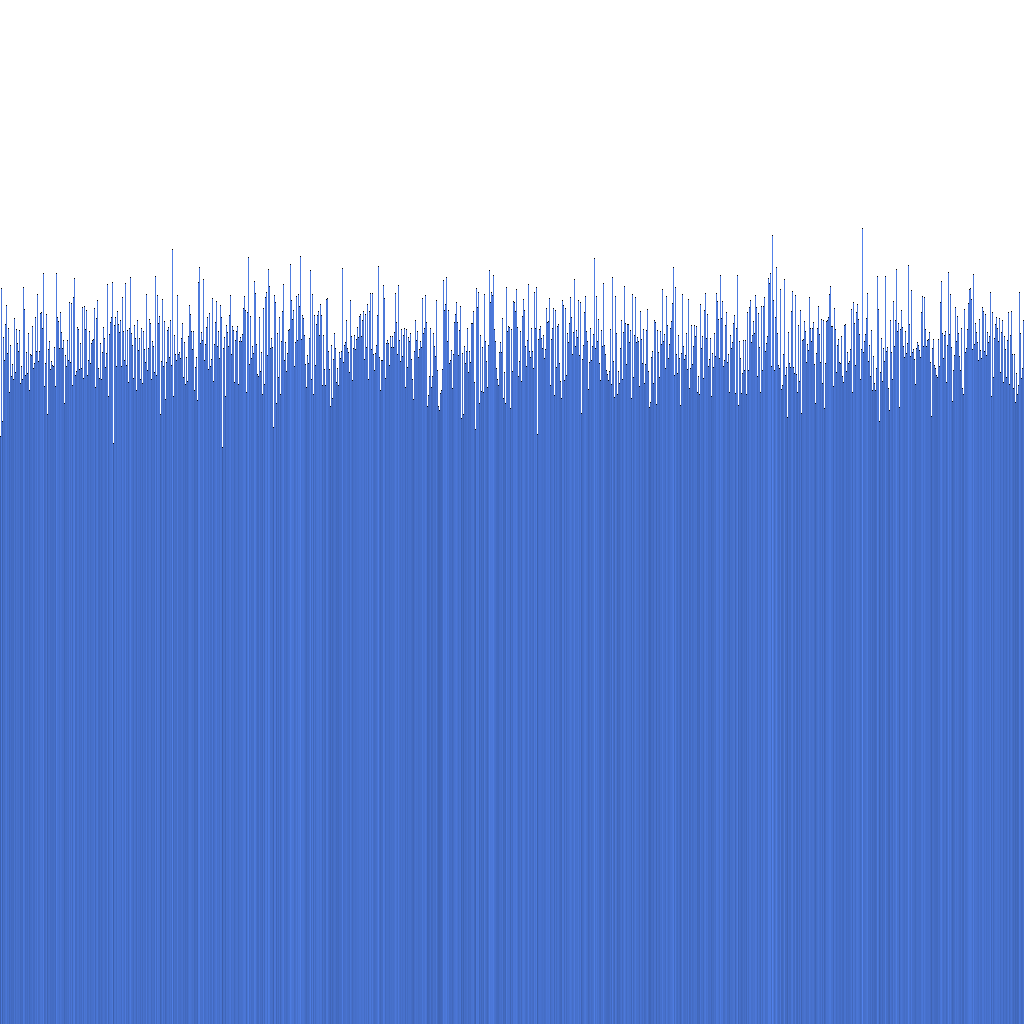
Pe baza histogramei de mai sus, putem observa că distribuția ID-urilor Randflake generate este foarte uniformă. Acest lucru sugerează că distribuția ID-urilor poate fi utilizată direct ca cheie de sharding.
Concluzie
În acest articol, am introdus Randflake, un algoritm nou de generare a ID-urilor care combină avantajele Snowflake și Sparx64.
Sperăm că acest articol v-a oferit o înțelegere cuprinzătoare a Randflake și a implementării sale.
Puteți găsi codul sursă complet pentru Randflake pe GitHub.
Dacă aveți întrebări sau sugestii, vă rugăm să nu ezitați să ne contactați. Căutăm, de asemenea, contribuitori care să ajute la îmbunătățirea Randflake și la implementarea acestuia în alte limbaje de programare.
Intenționăm să lansăm un serviciu de coordonare pregătit pentru producție pentru Randflake și Snowflake, care va fi open-source pe GitHub. Rămâneți pe fază pentru actualizări!