Представляем Randflake ID: распределенный, унифицированный, непредсказуемый, уникальный генератор случайных идентификаторов.
Рассмотрим ситуацию, когда нам необходимо сгенерировать уникальные 64-битные случайные числа, и внешние стороны не должны иметь возможность предсказать следующее или предыдущее число.
В данном случае мы можем сгенерировать 8-байтовое случайное значение, проверить, существует ли оно уже в базе данных, а затем сохранить его, если оно уникально.
Однако этот метод имеет несколько недостатков. Мы должны хранить каждое сгенерированное число в базе данных для обеспечения уникальности. Требование как минимум одного обращения к базе данных создает проблемы с задержкой, особенно в распределенной среде, где масштабируемость имеет решающее значение.
Для решения этих проблем мы представляем Randflake ID: распределенный, равномерный, непредсказуемый, уникальный генератор случайных ID.
Как работает Randflake ID?
Randflake ID вдохновлен Snowflake ID, широко используемым механизмом генерации k-сортированных ID, разработанным X (ранее twitter).
Snowflake ID использует текущую метку времени, ID узла и локальный счетчик для генерации идентификатора.
Мы расширили этот подход для генерации случайных уникальных ID и добавили новый элемент — секретный ключ.
Ключевая идея заключается в добавлении слоя блочного шифра к существующему генератору уникальных ID для достижения невозможности предсказания связи между числами.
Блочный шифр — это фундаментальная криптографическая функция, которая преобразует блок открытого текста фиксированной длины в блок шифротекста той же длины. Это преобразование регулируется криптографическим ключом. Отличительной характеристикой блочного шифра является его обратимость: он должен быть взаимно однозначной (биективной) функцией, гарантирующей, что каждый уникальный вход соответствует уникальному выходу, и наоборот. Это свойство имеет решающее значение для дешифрования, позволяя восстановить исходный открытый текст из шифротекста при применении правильного ключа.
Используя блочный шифр как взаимно однозначную функцию, мы можем гарантировать, что каждый уникальный вход производит соответствующий уникальный выход в пределах определенного диапазона.
Структура и соображения по проектированию
Основываясь на этих фундаментальных концепциях, рассмотрим, как Randflake ID реализует эти идеи на практике.
Структура Randflake ID включает 30-битную метку времени Unix с точностью до секунды, 17-битный идентификатор узла, 17-битный локальный счетчик и 64-битный блочный шифр, основанный на алгоритме sparx64.
Ниже приведены некоторые проектные решения:
Некоторые экземпляры VM в Google Cloud Platform могут синхронизировать часы с точностью до 0,2 мс, но такой уровень точности недоступен в общедоступном интернете или у других облачных провайдеров.
Мы выбрали точность до секунды, потому что можем эффективно синхронизировать часы между узлами только с разрешением в несколько миллисекунд.
17-битный идентификатор узла позволяет использовать 131072 отдельных генератора одновременно, которые могут быть назначены на процесс, на ядро, на поток.
В высокопроизводительных системах 17-битный локальный счетчик может быть недостаточным. Для обеспечения соответствующей пропускной способности мы можем назначить несколько генераторов, каждый с отдельным ID узла, для работы в одном процессе или потоке.
Мы приняли sparx64 в качестве 64-битного блочного шифра, современного легковесного блочного шифра на основе ARX.
Randflake ID предлагают внутреннюю отслеживаемость, раскрывая ID узла-источника и метку времени только тем, кто обладает секретным ключом.
Теоретическая максимальная пропускная способность составляет 17 179 869 184 ID/с, что достаточно для большинства приложений глобального масштаба.
Псевдокод генерации Randflake ID
Для более наглядной демонстрации процесса генерации Randflake ID, следующий псевдокод на Python предоставляет упрощенную реализацию:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Воскресенье, 27 октября 2024 г., 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 бит для метки времени (срок службы 34 года)
10RANDFLAKE_NODE_BITS = 17 # 17 бит для ID узла (макс. 131072 узлов)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 бит для последовательности (макс. 131072 последовательностей)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Готовая к производству реализация Randflake, включающая механизм аренды ID узла, доступна на GitHub.
Другие соображения
В этом разделе мы обсудим некоторые дополнительные соображения по реализации Randflake ID.
Координация ID узлов
Мы предлагаем координацию ID узлов на основе аренды.
В этом подходе центральная служба координации назначает уникальный ID узла каждому генератору.
Этот ID узла не переназначается в течение периода аренды для обеспечения уникальности, что снижает необходимость частого взаимодействия со службой координации.
Генератор, владеющий арендой, может запросить продление аренды у службы координации, если условие продления выполнено.
Условие продления относится к набору критериев, которые должны быть соблюдены для продления аренды, например, активность генератора и потребность в ID узла.
Арендатор — это текущий владелец диапазона ID узлов.
Аренда считается активной и не истекшей, если она находится в пределах своего действительного временного периода.
Таким образом, мы можем сократить количество обращений до одного за период продления аренды, минимизируя задержку и повышая эффективность в распределенных системах.
Снижение рисков, связанных с неисправными часами
Служба аренды должна проверять согласованность меток времени при выделении аренды. Назначенное время начала аренды должно быть больше или равно времени начала последней аренды.
Генератор должен отклонить запрос, если текущая метка времени меньше времени начала аренды или больше времени окончания аренды.
Эта процедура важна для защиты уникальности сгенерированных ID, когда часы перескакивают назад. Например, если часы перескакивают назад, новая аренда может быть назначена с временем начала, предшествующим ранее назначенной аренде, что потенциально может привести к генерации дубликатов ID. Отклоняя запросы с метками времени в пределах существующего периода аренды, мы предотвращаем этот сценарий и сохраняем уникальность ID.
Равномерность распределения ID
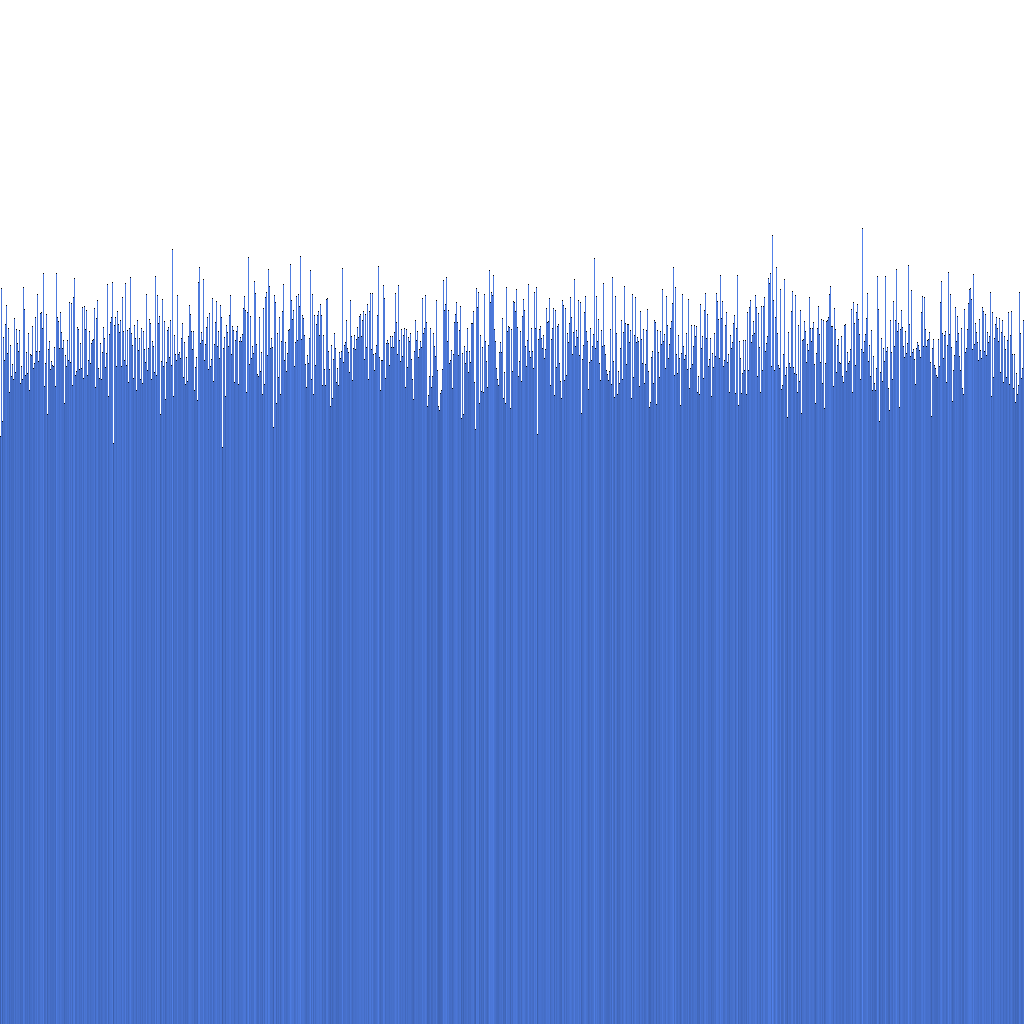
На основе гистограммы выше мы можем видеть, что распределение сгенерированных Randflake ID очень равномерно. Это предполагает, что распределение ID может быть использовано непосредственно в качестве ключа шардирования.
Заключение
В этой статье мы представили Randflake, новый алгоритм генерации ID, который сочетает в себе преимущества Snowflake и Sparx64.
Мы надеемся, что эта статья предоставила вам всестороннее понимание Randflake и его реализации.
Полный исходный код Randflake можно найти на GitHub.
Если у вас есть вопросы или предложения, пожалуйста, не стесняйтесь обращаться. Мы также ищем участников, которые помогут улучшить Randflake и реализовать его на других языках программирования.
Мы планируем выпустить готовую к производству службу координации для Randflake и Snowflake, которая будет опубликована с открытым исходным кодом на GitHub. Следите за обновлениями!