Predstavujeme Randflake ID: distribuovaný, jednotný, nepredvídateľný, unikátny generátor náhodných ID.
Zvážte situáciu, kde potrebujeme generovať unikátne 64-bitové náhodné čísla a externé strany by nemali byť schopné predpovedať nasledujúce ani predchádzajúce číslo.
V tomto prípade môžeme vygenerovať 8-bajtovú náhodnú hodnotu, skontrolovať, či už existuje v databáze, a potom ju uložiť, ak je unikátna.
Táto metóda má však niekoľko nevýhod. Musíme ukladať každé vygenerované číslo do databázy, aby sme zabezpečili jedinečnosť. Požiadavka na aspoň jednu komunikáciu s databázou vytvára problémy s latenciou, najmä v distribuovanom prostredí, kde je škálovateľnosť kľúčová.
Na vyriešenie týchto problémov predstavujeme Randflake ID: distribuovaný, uniformný, nepredvídateľný, unikátny generátor náhodných ID.
Ako funguje Randflake ID?
Randflake ID je inšpirované Snowflake ID, široko používaným mechanizmom generovania k-zoradených ID vyvinutým spoločnosťou X (predtým twitter).
Snowflake ID používa aktuálnu časovú pečiatku, ID uzla a lokálny počítadlo na generovanie identifikátora.
Tento prístup sme ďalej rozšírili pre generovanie náhodných unikátnych ID a pridali sme nový prvok tajného kľúča.
Kľúčovou myšlienkou je pridanie vrstvy blokovej šifry k existujúcemu generátoru unikátnych ID na dosiahnutie nepredvídateľnosti vzťahu medzi číslami.
Bloková šifra je základná kryptografická funkcia, ktorá transformuje blok obyčajného textu s pevnou dĺžkou na blok šifrovaného textu rovnakej dĺžky. Táto transformácia sa riadi kryptografickým kľúčom. Rozlišovacou charakteristikou blokovej šifry je jej reverzibilita: musí byť jedno-jednoznačná (bijektívna) funkcia, zabezpečujúca, že každý unikátny vstup zodpovedá unikátnemu výstupu a naopak. Táto vlastnosť je kľúčová pre dešifrovanie, umožňujúc obnovenie pôvodného obyčajného textu zo šifrovaného textu po aplikovaní správneho kľúča.
Použitím blokovej šifry ako jedno-jednoznačnej funkcie môžeme zaručiť, že každý unikátny vstup produkuje zodpovedajúci unikátny výstup v rámci definovaného rozsahu.
Štruktúra a úvahy o návrhu
Na základe týchto základných konceptov preskúmajme, ako Randflake ID implementuje tieto myšlienky v praxi.
Štruktúra Randflake ID zahŕňa 30-bitovú unixovú časovú pečiatku s presnosťou na sekundu, 17-bitový identifikátor uzla, 17-bitový lokálny počítadlo a 64-bitovú blokovú šifru založenú na algoritme sparx64.
Tu sú niektoré rozhodnutia o návrhu:
Niektoré inštancie VM v Google Cloud Platform dokážu synchronizovať hodiny s presnosťou 0.2ms, avšak táto úroveň presnosti nie je dostupná na verejnom internete alebo u iných poskytovateľov cloudu.
Zvolili sme presnosť na sekundu, pretože hodiny medzi uzlami dokážeme efektívne synchronizovať iba s rozlíšením niekoľkých milisekúnd.
17-bitový identifikátor uzla umožňuje 131072 individuálnych generátorov v rovnakom momente, ktoré môžu byť priradené na základe procesu, jadra alebo vlákna.
V systémoch s vysokou priepustnosťou môže byť 17-bitový lokálny počítadlo nedostatočný. Na dosiahnutie požadovanej priepustnosti môžeme priradiť viacero generátorov, každý s odlišným ID uzla, aby pracovali v jednom procese alebo vlákne.
Prijali sme sparx64 ako 64-bitovú blokovú šifru, modernú ľahkú blokovú šifru založenú na ARX.
Randflake ID ponúkajú internú sledovateľnosť, odhaľujúc svoje pôvodné ID uzla a časovú pečiatku iba tým, ktorí vlastnia tajný kľúč.
Teoretická maximálna priepustnosť je 17 179 869 184 ID/s, čo je dostatočné pre väčšinu aplikácií globálneho rozsahu.
Pseudokód generovania Randflake ID
Na ďalšie ilustrovanie procesu generovania Randflake ID, nasledujúci Python pseudokód poskytuje zjednodušenú implementáciu:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Sunday, October 27, 2024 3:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bitov pre časovú pečiatku (životnosť 34 rokov)
10RANDFLAKE_NODE_BITS = 17 # 17 bitov pre ID uzla (max 131072 uzlov)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bitov pre sekvenciu (max 131072 sekvencií)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Produkčná implementácia Randflake, obsahujúca mechanizmus prenájmu ID uzla, je dostupná na GitHub.
Ďalšie úvahy
V tejto sekcii prediskutujeme niektoré dodatočné úvahy pre implementáciu Randflake ID.
Koordinácia ID uzlov
Navrhujeme koordináciu ID uzlov na báze prenájmu.
Pri tomto prístupe centrálna koordinačná služba prideľuje každému generátoru unikátne ID uzla.
Toto ID uzla sa počas doby prenájmu nepriraďuje znova, aby sa zabezpečila jedinečnosť, čím sa znižuje potreba častých komunikácií s koordinačnou službou.
Generátor, ktorý drží prenájom, môže požiadať o obnovenie prenájmu od koordinačnej služby, ak sú splnené podmienky obnovenia.
Podmienka obnovenia sa vzťahuje na súbor kritérií, ktoré musia byť splnené pre obnovenie prenájmu, ako napríklad, že generátor je stále aktívny a vyžaduje ID uzla.
Držiteľ prenájmu je aktuálny držiteľ rozsahu ID uzlov.
Prenájom sa považuje za aktívny a nevypršaný, ak je v rámci svojho platného časového obdobia.
Týmto spôsobom môžeme znížiť počet obojsmerných komunikácií na jednu za obdobie obnovenia prenájmu, čím minimalizujeme latenciu a zlepšujeme efektivitu v distribuovaných systémoch.
Zmiernenie rizika chybného hodinového systému
Služba prenájmu musí kontrolovať konzistenciu časovej pečiatky pri prideľovaní prenájmu. Priradený čas začiatku prenájmu musí byť väčší alebo rovný času začiatku posledného prenájmu.
Generátor by mal odmietnuť požiadavku, ak je aktuálna časová pečiatka menšia ako čas začiatku prenájmu alebo väčšia ako čas konca prenájmu.
Tento postup je dôležitý na ochranu jedinečnosti generovaných ID v prípade, že sa hodiny posunú dozadu. Napríklad, ak sa hodiny posunú dozadu, nový prenájom by mohol byť pridelený s časom začiatku skôr ako predtým pridelený prenájom, čo by potenciálne viedlo k generovaniu duplicitných ID. Odmietaním požiadaviek s časovými pečiatkami v rámci existujúceho obdobia prenájmu predchádzame tomuto scenáru a udržiavame jedinečnosť ID.
Uniformita distribúcie ID
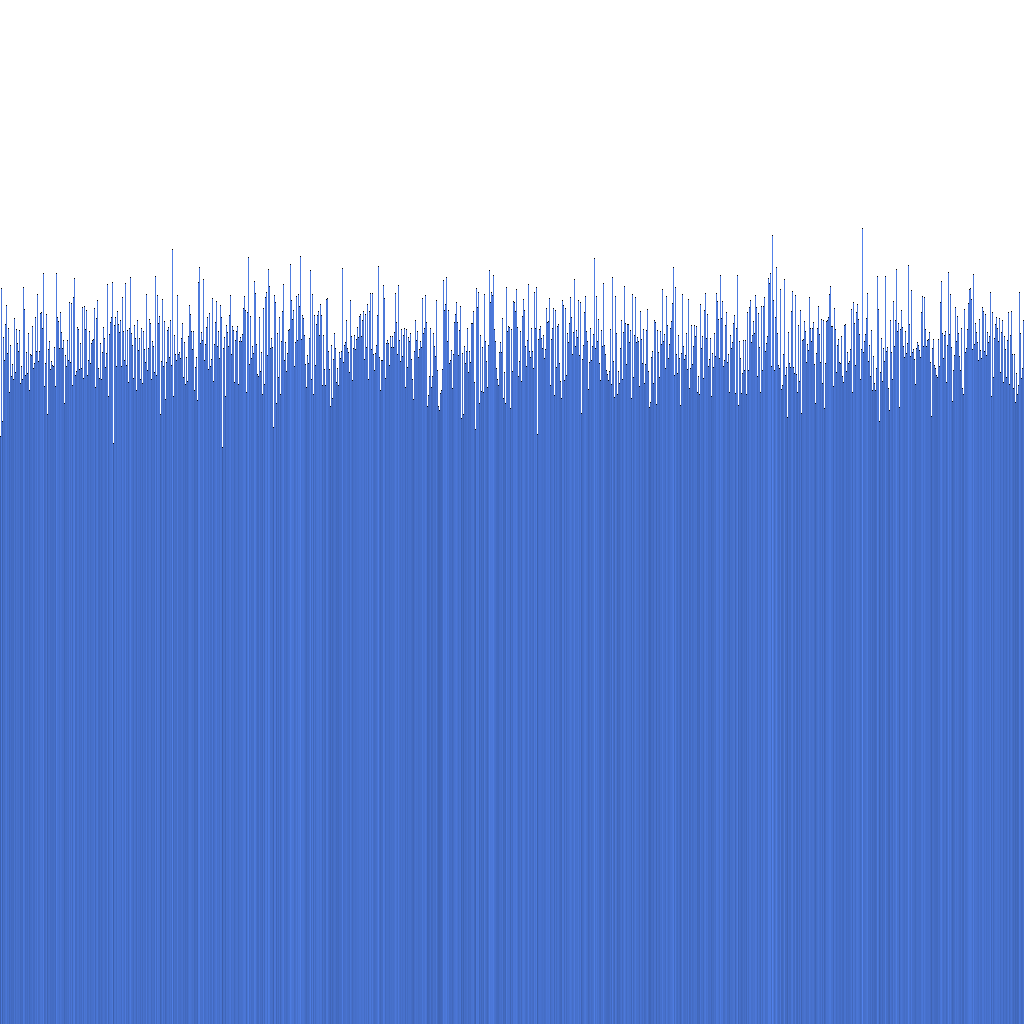
Na základe vyššie uvedeného histogramu môžeme vidieť, že distribúcia generovaných Randflake ID je veľmi uniformná. To naznačuje, že distribúcia ID môže byť priamo použitá ako sharding key.
Záver
V tomto článku sme predstavili Randflake, nový algoritmus generovania ID, ktorý kombinuje výhody Snowflake a Sparx64.
Dúfame, že tento článok vám poskytol komplexné pochopenie Randflake a jeho implementácie.
Celý zdrojový kód pre Randflake nájdete na GitHub.
Ak máte akékoľvek otázky alebo návrhy, neváhajte nás kontaktovať. Hľadáme tiež prispievateľov, ktorí by pomohli vylepšiť Randflake a implementovať ho v iných programovacích jazykoch.
Plánujeme vydať produkčnú koordinačnú službu pre Randflake a Snowflake, ktorá bude open-source na GitHub-e. Sledujte aktuálne informácie!