Introduktion av Randflake ID: en distribuerad, enhetlig, oförutsägbar, unik slumptals-ID-generator.
Betrakta en situation där vi behöver generera unika 64-bitars slumptal, och externa parter inte ska kunna förutsäga nästa eller föregående nummer.
Här kan vi generera ett 8-byte slumpmässigt värde, kontrollera om det redan finns i databasen och sedan lagra det om det är unikt.
Denna metod har dock flera nackdelar. Vi måste lagra varje genererat nummer i en databas för att säkerställa unikhet. Kravet på minst en tur och retur till databasen skapar latensproblem, särskilt i en distribuerad miljö där skalbarhet är avgörande.
För att lösa dessa problem introducerar vi Randflake ID: en distribuerad, enhetlig, oförutsägbar, unik slumpmässig ID-generator.
Hur fungerar Randflake ID?
Randflake ID är inspirerad av Snowflake ID, den allmänt använda k-sorterade ID-genereringsmekanismen utvecklad av X (tidigare Twitter).
Snowflake ID använder aktuell tidsstämpel, ett node ID och en lokal räknare för att generera en identifierare.
Vi utökade denna metod ytterligare för slumpmässig unik ID-generering och lade till ett nytt hemligt nyckelelement.
Huvudidén är att lägga till ett block cipher-skikt till den befintliga unika ID-generatorn för att uppnå omöjlighet att förutsäga förhållandet mellan nummer.
En block cipher är en grundläggande kryptografisk funktion som omvandlar ett block av klartext med fast längd till ett block av chiffertext med samma längd. Denna omvandling styrs av en kryptografisk nyckel. Den utmärkande egenskapen hos en block cipher är dess reversibilitet: den måste vara en en-till-en (bijektiv) funktion, vilket säkerställer att varje unik inmatning motsvarar en unik utmatning, och vice versa. Denna egenskap är avgörande för dekryptering, vilket möjliggör att den ursprungliga klartexten kan återställas från chiffertexten när rätt nyckel tillämpas.
Genom att använda en block cipher som en en-till-en-funktion kan vi garantera att varje unik inmatning producerar en motsvarande unik utmatning inom det definierade intervallet.
Strukturen och designöverväganden
Med utgångspunkt i dessa grundläggande koncept, låt oss undersöka hur Randflake ID implementerar dessa idéer i praktiken.
Randflake ID-strukturen inkluderar en 30-bitars Unix-tidsstämpel med sekundprecision, en 17-bitars nodidentifierare, en 17-bitars lokal räknare och en 64-bitars block cipher baserad på sparx64-algoritmen.
Här är några designbeslut:
Vissa VM-instanser i Google Cloud Platform kan synkronisera klockan med 0,2 ms precision, men den nivån av noggrannhet är inte tillgänglig på det offentliga internet eller hos andra molnleverantörer.
Vi valde en sekundprecision eftersom vi effektivt kan synkronisera klockan mellan noder endast inom några millisekunders upplösning.
17-bitars nodidentifierare tillåter 131072 individuella generatorer samtidigt, som kan tilldelas per process, per kärna, per tråd.
I system med hög genomströmning kan 17-bitars lokal räknare vara otillräcklig. För att matcha genomströmningen kan vi tilldela flera generatorer, var och en med ett distinkt nod-ID, för att arbeta i en enda process eller tråd.
Vi antog sparx64 som en 64-bitars block cipher, en modern lättviktig ARX-baserad block cipher.
Randflake ID erbjuder intern spårbarhet, vilket avslöjar deras ursprungliga nod-ID och tidsstämpel endast för dem som innehar den hemliga nyckeln.
Teoretisk maximal genomströmning är 17 179 869 184 ID/s, vilket är tillräckligt för de flesta globala applikationer.
Pseudokod för Randflake ID-generering
För att ytterligare illustrera Randflake ID-genereringsprocessen, tillhandahåller följande Python-pseudokod en förenklad implementering:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Constants
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Söndag, 27 oktober 2024 03:33:20 AM UTC
7
8# Bits allocation
9RANDFLAKE_TIMESTAMP_BITS = 30 # 30 bitar för tidsstämpel (livslängd 34 år)
10RANDFLAKE_NODE_BITS = 17 # 17 bitar för nod-id (max 131072 noder)
11RANDFLAKE_SEQUENCE_BITS = 17 # 17 bitar för sekvens (max 131072 sekvenser)
12
13# Derived constants
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
En produktionsklar implementering av Randflake, med en lease-mekanism för nod-ID, finns tillgänglig på GitHub.
Andra överväganden
I det här avsnittet kommer vi att diskutera några ytterligare överväganden för implementering av Randflake ID.
Nod-ID-koordinering
Vi föreslår lease-baserad nod-ID-koordinering.
I denna metod tilldelar en central koordineringstjänst ett unikt nod-ID till varje generator.
Detta nod-ID återtilldelas inte under lease-perioden för att säkerställa unikhet, vilket minskar behovet av frekvent kommunikation med koordineringstjänsten.
Generatorn som innehar leasen kan begära en förnyelse av leasen från koordineringstjänsten om förnyelsevillkoret är uppfyllt.
Förnyelsevillkoret avser en uppsättning kriterier som måste uppfyllas för att leasen ska förnyas, till exempel att generatorn fortfarande är aktiv och behöver nod-ID:t.
Leasehållaren är den nuvarande innehavaren av nod-ID-intervallet.
Leasen anses vara aktiv och inte utgången om den ligger inom sin giltiga tidsperiod.
På detta sätt kan vi minska antalet tur-och-retur-resor till en per förnyelseperiod, vilket minimerar latensen och förbättrar effektiviteten i distribuerade system.
Mildring mot felaktig klocka
Leasetjänsten måste kontrollera tidsstämpelkonsistens vid tilldelning av en lease. Den tilldelade leasens starttid måste vara större än eller lika med den senaste leasens starttid.
Generatorn bör avvisa begäran om den aktuella tidsstämpeln är mindre än leasens starttid eller större än leasens sluttid.
Denna procedur är viktig för att skydda unikheten hos genererade ID:n när klockan hoppar bakåt. Om till exempel en klocka hoppar bakåt, kan en ny lease tilldelas med en starttid som är tidigare än en tidigare tilldelad lease, vilket potentiellt kan leda till att dubbletter av ID:n genereras. Genom att avvisa begäranden med tidsstämplar inom en befintlig leaseperiod förhindrar vi detta scenario och upprätthåller ID:nas unikhet.
Enhetlighet i ID-distribution
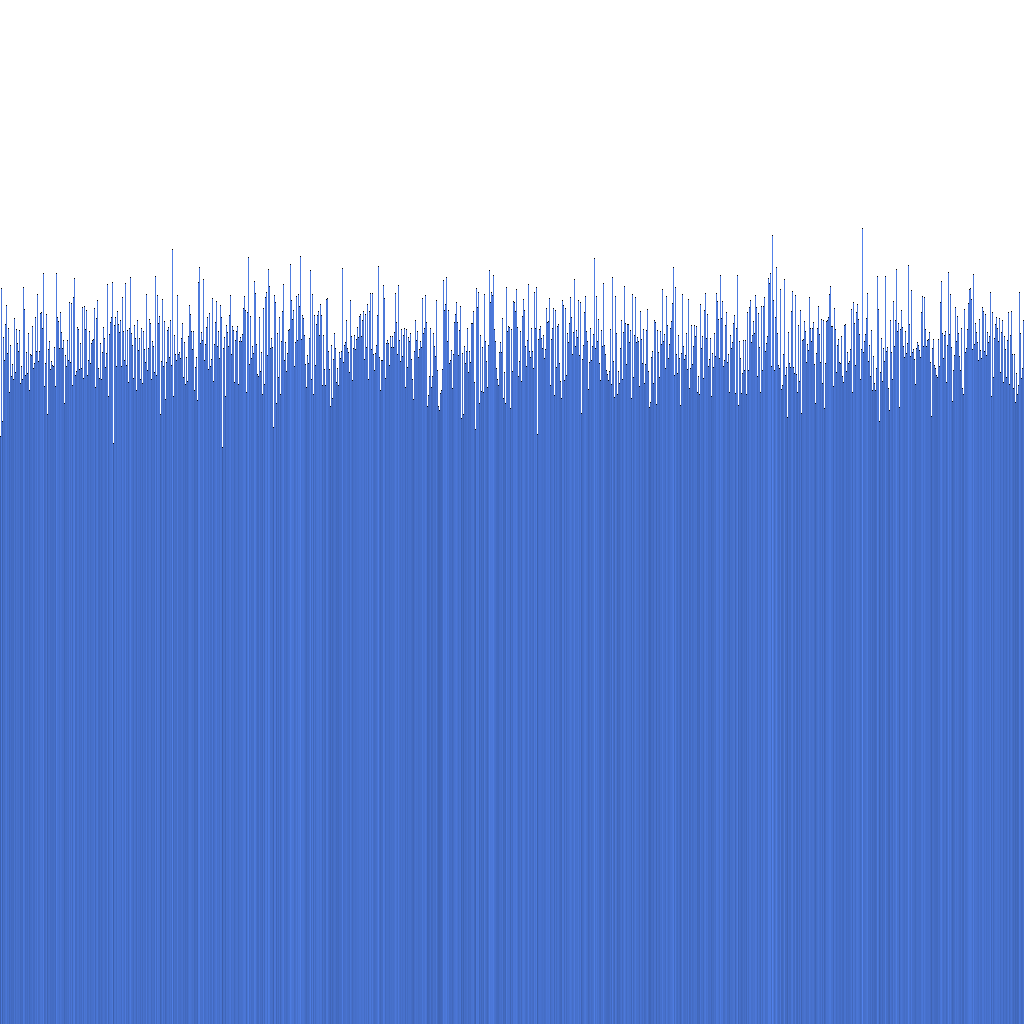
Baserat på histogrammet ovan kan vi se att fördelningen av genererade Randflake ID:n är mycket enhetlig. Detta tyder på att ID-distributionen kan användas direkt som en sharding key.
Slutsats
I den här artikeln introducerade vi Randflake, en ny algoritm för ID-generering som kombinerar fördelarna med Snowflake och Sparx64.
Vi hoppas att denna artikel har gett dig en omfattande förståelse för Randflake och dess implementering.
Du hittar hela källkoden för Randflake på GitHub.
Om du har några frågor eller förslag, tveka inte att kontakta oss. Vi söker också bidragsgivare för att hjälpa till att förbättra Randflake och implementera det i andra programmeringsspråk.
Vi planerar att släppa en produktionsklar koordineringstjänst för Randflake och Snowflake, som kommer att vara open source på GitHub. Håll utkik efter uppdateringar!