Randflake ID'yi Tanıtıyoruz: dağıtılmış, tekdüze, öngörülemeyen, benzersiz bir rastgele ID üreteci.
Benzersiz 64-bit rastgele sayılar üretmemiz ve harici tarafların bir sonraki veya bir önceki sayıyı tahmin edememesi gereken bir durumu ele alalım.
Burada, 8-baytlık rastgele bir değer üretebilir, veritabanında zaten mevcut olup olmadığını kontrol edebilir ve benzersiz ise saklayabiliriz.
Ancak, bu yöntemin çeşitli dezavantajları bulunmaktadır. Benzersizliği sağlamak için üretilen her sayıyı bir veritabanında saklamamız gerekmektedir. Veritabanına en az bir gidiş-dönüş gereksinimi, özellikle ölçeklenebilirliğin kritik olduğu dağıtık bir ortamda gecikme sorunları yaratmaktadır.
Bu sorunları çözmek için Randflake ID'yi sunuyoruz: dağıtık, tekdüze, öngörülemez, benzersiz bir rastgele ID üreticisi.
Randflake ID Nasıl Çalışır?
Randflake ID, X (eski adıyla Twitter) tarafından geliştirilen, yaygın olarak kullanılan k-sıralı ID üretim mekanizması olan Snowflake ID'den esinlenmiştir.
Snowflake ID, bir tanımlayıcı oluşturmak için mevcut zaman damgasını, bir node ID'sini ve yerel bir sayacı kullanır.
Bu yaklaşımı rastgele benzersiz ID üretimi için daha da genişlettik ve yeni bir gizli anahtar öğesi ekledik.
Temel fikir, sayılar arasındaki ilişkiyi tahmin etmenin imkansızlığını sağlamak için mevcut benzersiz ID üreticisine bir block cipher katmanı eklemektir.
Bir block cipher, sabit uzunluktaki bir plaintext bloğunu aynı uzunluktaki bir ciphertext bloğuna dönüştüren temel bir kriptografik fonksiyondur. Bu dönüşüm bir kriptografik anahtar tarafından yönetilir. Bir block cipher'ın ayırt edici özelliği tersine çevrilebilirliğidir: her benzersiz girdinin benzersiz bir çıktıya karşılık geldiğini ve bunun tersini sağlayan birebir (bijective) bir fonksiyon olmalıdır. Bu özellik, doğru anahtar uygulandığında orijinal plaintext'in ciphertext'ten kurtarılmasını sağladığı için şifre çözme için hayati öneme sahiptir.
Bir block cipher'ı birebir bir fonksiyon olarak kullanarak, tanımlanan aralık içinde her benzersiz girdinin karşılık gelen benzersiz bir çıktı üreteceğini garanti edebiliriz.
Yapı ve tasarım değerlendirmesi
Bu temel kavramlar üzerine inşa ederek, Randflake ID'nin bu fikirleri pratikte nasıl uyguladığını inceleyelim.
Randflake ID yapısı, saniye hassasiyetinde 30-bitlik bir Unix zaman damgası, 17-bitlik bir node identifier, 17-bitlik bir yerel sayaç ve sparx64 algoritmasına dayalı 64-bitlik bir block cipher içerir.
İşte bazı tasarım kararları:
Google Cloud Platform'daki bazı VM örnekleri saati 0.2ms hassasiyetle senkronize edebilir, ancak bu hassasiyet seviyesi genel internette veya diğer bulut sağlayıcılarında mevcut değildir.
Saniye hassasiyetini seçtik çünkü düğümler arasındaki saati yalnızca birkaç milisaniye çözünürlük içinde etkili bir şekilde senkronize edebiliriz.
17-bit node identifier, aynı anda 131072 ayrı jeneratöre izin verir ve bu, işlem başına, çekirdek başına veya iş parçacığı başına atanabilir.
Yüksek verimli sistemlerde, 17-bit yerel sayaç yetersiz olabilir. Verimi karşılamak için, tek bir işlem veya iş parçacığında çalışmak üzere her biri farklı bir node ID'ye sahip birden çok jeneratör atayabiliriz.
Modern hafif bir ARX tabanlı block cipher olan sparx64'ü 64-bit block cipher olarak benimsedik.
Randflake ID'ler, yalnızca gizli anahtara sahip olanlara kaynak node ID'sini ve zaman damgasını gösteren dahili izlenebilirlik sunar.
Teorik maksimum verim 17,179,869,184 ID/s'dir ve bu çoğu küresel ölçekli uygulama için yeterlidir.
Randflake ID üretiminin sözde kodu
Randflake ID üretim sürecini daha iyi açıklamak için, aşağıdaki Python pseudocode basitleştirilmiş bir uygulama sunmaktadır:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# Sabitler
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # Pazar, 27 Ekim 2024 3:33:20 AM UTC
7
8# Bit tahsisi
9RANDFLAKE_TIMESTAMP_BITS = 30 # Zaman damgası için 30 bit (34 yıllık ömür)
10RANDFLAKE_NODE_BITS = 17 # Node ID için 17 bit (maks. 131072 düğüm)
11RANDFLAKE_SEQUENCE_BITS = 17 # Sequence için 17 bit (maks. 131072 sequence)
12
13# Türetilmiş sabitler
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Node ID kiralama mekanizmasına sahip, üretime hazır bir Randflake uygulaması GitHub adresinde mevcuttur.
Diğer hususlar
Bu bölümde, Randflake ID'yi uygulamak için bazı ek hususları tartışacağız.
Node ID koordinasyonu
Kira tabanlı node ID koordinasyonunu öneriyoruz.
Bu yaklaşımda, merkezi bir koordinasyon hizmeti her jeneratöre benzersiz bir node ID atar.
Bu node ID, benzersizliği sağlamak için kira süresi boyunca yeniden atanmaz ve koordinasyon hizmetiyle sık iletişime olan ihtiyacı azaltır.
Kirayı elinde tutan jeneratör, yenileme koşulu karşılandığı takdirde koordinasyon hizmetinden kiranın yenilenmesini talep edebilir.
Yenileme koşulu, kiranın yenilenmesi için karşılanması gereken bir dizi kriteri ifade eder; örneğin, jeneratörün hala aktif olması ve node ID'ye ihtiyaç duyması gibi.
Kira sahibi, node ID aralığının mevcut sahibidir.
Kira, geçerli zaman aralığı içinde ise aktif ve süresi dolmamış kabul edilir.
Bu şekilde, gidiş-dönüşleri kira yenileme dönemi başına bire düşürerek, dağıtık sistemlerde gecikmeyi en aza indirebilir ve verimliliği artırabiliriz.
Arızalı saate karşı hafifletme
Kira hizmeti, kira tahsis ederken zaman damgası tutarlılığını kontrol etmelidir. Atanan kira başlangıç zamanı, son kira başlangıç zamanından büyük veya ona eşit olmalıdır.
Jeneratör, mevcut zaman damgası kira başlangıç zamanından küçükse veya kira bitiş zamanından büyükse isteği reddetmelidir.
Bu prosedür, saat geriye sıçradığında üretilen ID'lerin benzersizliğini korumak için önemlidir. Örneğin, saat geriye sıçrarsa, daha önce atanmış bir kiranın başlangıç zamanından daha erken bir başlangıç zamanına sahip yeni bir kira atanabilir ve bu da potansiyel olarak yinelenen ID'lerin üretilmesine yol açabilir. Mevcut bir kira dönemi içindeki zaman damgalarına sahip istekleri reddederek bu senaryoyu önler ve ID'lerin benzersizliğini koruruz.
ID dağılımının tekdüzeliği
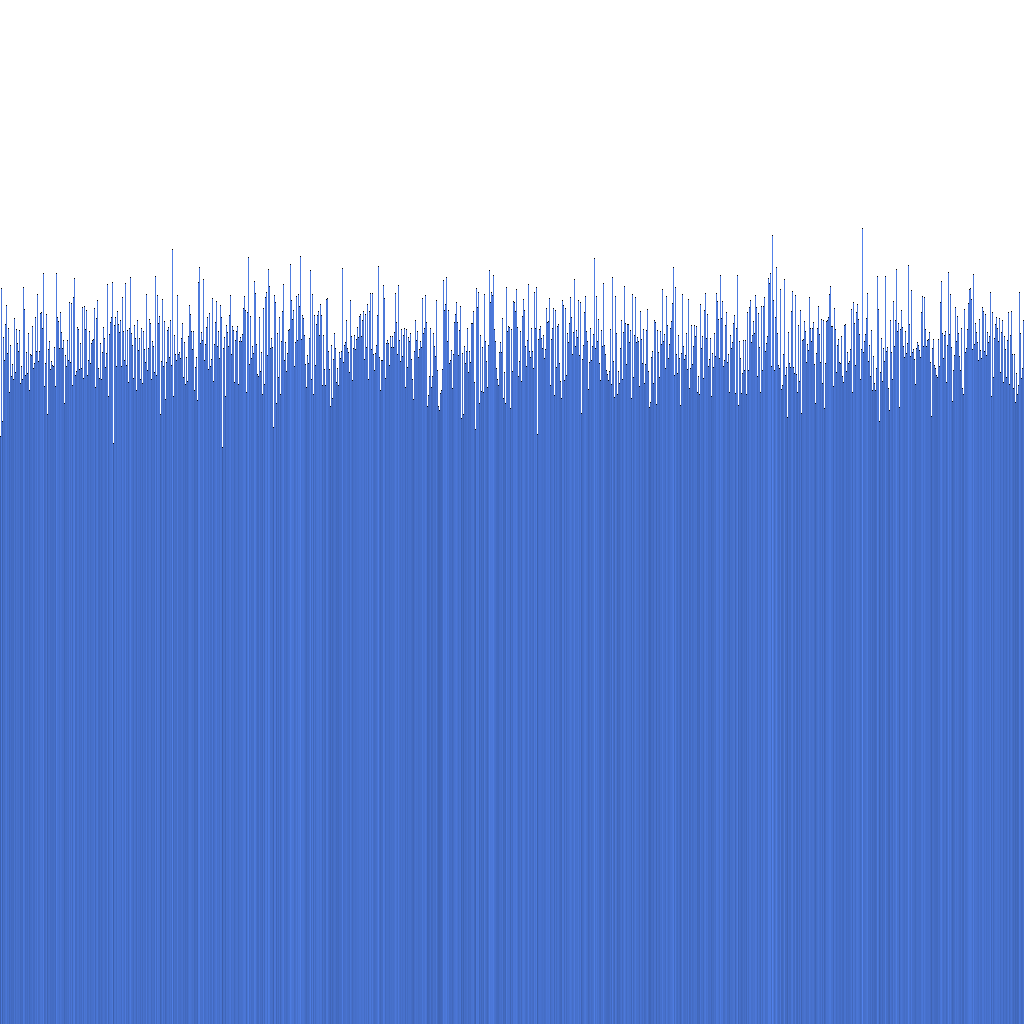
Yukarıdaki histograma dayanarak, üretilen Randflake ID'lerinin dağılımının çok tekdüze olduğunu görebiliriz. Bu, ID dağılımının doğrudan bir sharding anahtarı olarak kullanılabileceğini düşündürmektedir.
Sonuç
Bu makalede, Snowflake ve Sparx64'ün avantajlarını birleştiren yeni bir ID üretim algoritması olan Randflake'i tanıttık.
Bu makalenin size Randflake ve uygulamasının kapsamlı bir anlayışını sağladığını umuyoruz.
Randflake'in tam kaynak kodunu GitHub adresinde bulabilirsiniz.
Herhangi bir sorunuz veya öneriniz varsa, lütfen bizimle iletişime geçmekten çekinmeyin. Randflake'i geliştirmeye ve diğer programlama dillerinde uygulamaya yardımcı olacak katkıda bulunanlar da arıyoruz.
Randflake ve Snowflake için üretime hazır bir koordinasyon hizmeti yayınlamayı planlıyoruz ve bu hizmet GitHub'da açık kaynaklı olacak. Güncellemeler için bizi takipte kalın!