隆重推出 Randflake ID:一种分布式、统一、不可预测、唯一的随机 ID 生成器。
设想一个场景,我们需要生成唯一的64位随机数,且外部方无法预测下一个或上一个数字。
在此场景中,我们可以生成一个8字节的随机值,检查其是否已存在于数据库中,如果唯一则进行存储。
然而,此方法存在若干缺点。我们必须在数据库中存储所有生成的数字以确保唯一性。至少一次往返数据库的需求会产生延迟问题,特别是在可扩展性至关重要的分布式环境中。
为解决这些问题,我们引入了Randflake ID:一种分布式、统一、不可预测、唯一的随机ID生成器。
Randflake ID 的工作原理是什么?
Randflake ID 的灵感来源于Snowflake ID,这是一种由X(前身为Twitter)开发的广泛使用的k排序ID生成机制。
Snowflake ID 使用当前时间戳、节点ID和本地计数器来生成标识符。
我们进一步扩展了这种方法,用于随机唯一ID生成,并添加了一个新的密钥元素。
核心思想是在现有唯一ID生成器中增加一个分组密码层,以实现预测数字之间关系的不可能性。
分组密码是一种基础的密码学函数,它将固定长度的明文块转换为相同长度的密文块。此转换由一个密码密钥控制。分组密码的显著特征是其可逆性:它必须是一个一对一(双射)函数,确保每个唯一的输入对应一个唯一的输出,反之亦然。此特性对于解密至关重要,允许在应用正确密钥时从密文中恢复原始明文。
通过将分组密码用作一对一函数,我们可以保证每个唯一的输入在定义的范围内产生相应的唯一输出。
结构与设计考量
在这些基本概念的基础上,让我们研究Randflake ID如何在实践中实现这些思想。
Randflake ID 的结构包括一个30位以秒为精度Unix时间戳、一个17位节点标识符、一个17位本地计数器以及一个基于sparx64算法的64位分组密码。
以下是一些设计决策:
Google Cloud Platform 中的某些VM实例可以将时钟同步到0.2ms的精度,但这种精度在公共互联网或其他云提供商上不可用。
我们选择秒级精度,因为我们只能在几毫秒的精度范围内有效同步节点间的时钟。
17位节点标识符允许同时存在131072个独立的生成器,可以按进程、按核心、按线程分配。
在高吞吐量系统中,17位本地计数器可能不足。为匹配吞吐量,我们可以分配多个生成器,每个生成器具有不同的节点ID,在单个进程或线程中工作。
我们采用sparx64作为64位分组密码,这是一种现代轻量级基于ARX的分组密码。
Randflake ID 提供内部可追溯性,仅向拥有密钥的人员揭示其源节点ID和时间戳。
理论最大吞吐量为17,179,869,184 ID/s,这对于大多数全球规模的应用而言已足够。
Randflake ID 生成的伪代码
为进一步阐明Randflake ID的生成过程,以下Python伪代码提供了一个简化的实现:
1import time
2import struct
3from .sparx64 import Sparx64
4
5# 常量
6RANDFLAKE_EPOCH_OFFSET = 1730000000 # 协调世界时2024年10月27日星期日3:33:20
7
8# 位分配
9RANDFLAKE_TIMESTAMP_BITS = 30 # 时间戳占用30位(生命周期34年)
10RANDFLAKE_NODE_BITS = 17 # 节点ID占用17位(最多131072个节点)
11RANDFLAKE_SEQUENCE_BITS = 17 # 序列占用17位(最多131072个序列)
12
13# 派生常量
14RANDFLAKE_MAX_TIMESTAMP = RANDFLAKE_EPOCH_OFFSET + (1 << RANDFLAKE_TIMESTAMP_BITS) - 1
15RANDFLAKE_MAX_NODE = (1 << RANDFLAKE_NODE_BITS) - 1
16RANDFLAKE_MAX_SEQUENCE = (1 << RANDFLAKE_SEQUENCE_BITS) - 1
17
18class Randflake:
19 def __init__(self, node_id: int, secret: bytes):
20 self.node_id = int(node_id)
21 self.sequence = int(0)
22 self.rollover = int(time.time())
23 self.sbox = Sparx64(secret)
24
25 def _new_raw(self) -> int:
26 while True:
27 now = int(time.time())
28
29 self.sequence += 1
30 sequence = self.sequence
31
32 if sequence > RANDFLAKE_MAX_SEQUENCE:
33 if now > self.rollover:
34 self.sequence = 0
35 self.rollover = now
36 sequence = 0
37 else:
38 continue
39
40 timestamp = now - RANDFLAKE_EPOCH_OFFSET
41 return (timestamp << 34) | (self.node_id << 17) | sequence
42
43 def generate(self) -> int:
44 id_raw = self._new_raw()
45 src = struct.pack("<q", id_raw)
46 dst = bytearray(8)
47 self.sbox.encrypt(dst, src)
48 return struct.unpack("<q", dst)[0]
Randflake 的生产就绪实现,包含节点ID租约机制,可在GitHub上获取。
其他考量
在本节中,我们将讨论实现Randflake ID的一些额外考量。
节点ID协调
我们建议采用基于租约的节点ID协调机制。
在此方法中,中央协调服务为每个生成器分配一个唯一的节点ID。
在租约期内,此节点ID不会被重新分配以确保唯一性,从而减少了与协调服务频繁通信的需求。
如果满足续租条件,持有租约的生成器可以向协调服务请求续租。
续租条件是指租约续期必须满足的一系列标准,例如生成器仍处于活动状态并需要该节点ID。
租约持有人是节点ID范围的当前持有人。
如果租约在其有效时间段内,则被视为活动且未过期。
通过这种方式,我们可以将每次租约续期期间的往返次数减少到一次,从而最大程度地降低分布式系统中的延迟并提高效率。
针对时钟故障的缓解措施
租约服务在分配租约时必须检查时间戳一致性。分配的租约开始时间必须大于或等于上次租约开始时间。
如果当前时间戳小于租约开始时间或大于租约结束时间,生成器应拒绝该请求。
当时间回跳时,此程序对于保护生成ID的唯一性至关重要。例如,如果时钟回跳,可能会分配一个开始时间早于先前分配租约的新租约,这可能导致生成重复的ID。通过拒绝时间戳位于现有租约期内的请求,我们阻止了这种情况的发生,并维护了ID的唯一性。
ID分布的均匀性
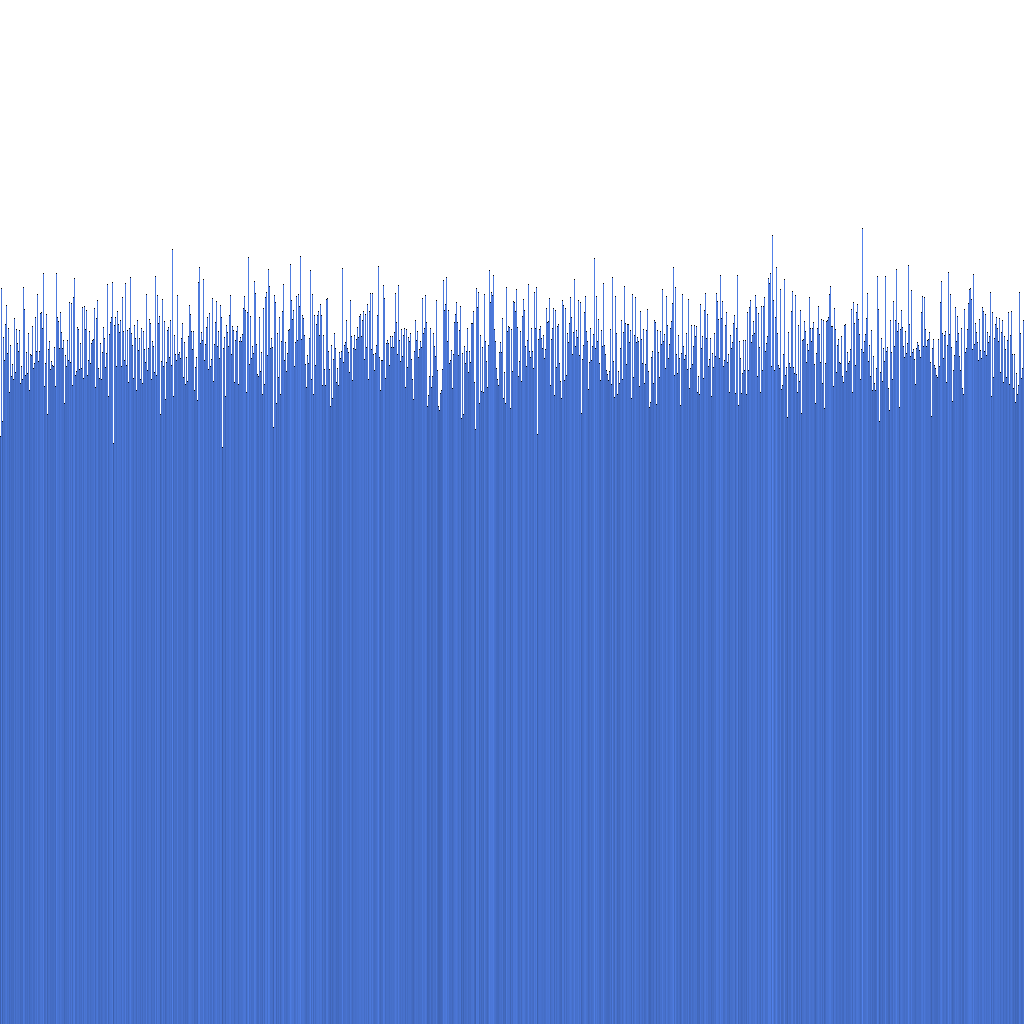
根据上方的直方图,我们可以看到生成的Randflake ID的分布非常均匀。这表明ID分布可以直接用作分片键。
结论
在本文中,我们介绍了Randflake,这是一种新颖的ID生成算法,它结合了Snowflake和Sparx64的优点。
我们希望本文能让您全面理解Randflake及其实现。
您可以在GitHub上找到Randflake的完整源代码。
如果您有任何问题或建议,请随时联系我们。我们也在寻找贡献者,以帮助改进Randflake并将其实现到其他编程语言中。
我们计划发布一个用于Randflake和Snowflake的生产就绪协调服务,该服务将在GitHub上开源。敬请关注更新!